Timescale 产品的最新功能和更新。
2025 年 2 月 14 日在 Timescale Cloud 中创建的新服务现在使用 TimescaleDB v2.18.1。现有服务将在下周开始的下一个维护窗口中自动升级。
此新版本包含许多错误修复和小改进,包括
- 使用 hypercore 表访问方法时更快的列式扫描
- 确保在列存储上删除数据时始终应用所有约束
- 在列存储上推送 UPDATE/DELETE 操作扫描的所有过滤器
Timescale Cloud 现在完全支持 AWS Transit Gateway,使其更易于将您的数据库安全地连接到跨不同环境(包括 AWS、本地和其他云提供商)的多个 VPC。
通过此更新,您可以在您的 Timescale Cloud 服务和您 AWS 账户中的 AWS Transit Gateway 之间建立对等连接。这使您的 Timescale Cloud 服务安全地位于 VPC 后,同时允许跨复杂网络设置的无缝访问。
2025 年 2 月 6 日从本周开始,在 Timescale Cloud 上创建的所有新服务都使用 TimescaleDB v2.18。现有服务将在其维护窗口期间逐步升级。
TimescaleDB v2.18.0 中的突出功能包括
- 通过新的 hypercore 表访问方法向列存储添加密集索引(btree 和 hash)的能力。
- 通过向量化 (SIMD) 显著提升性能,用于在使用 group by 和单列和/或在使用过滤器子句查询列存储时进行聚合。
- 超表支持转换表的触发器,这是社区最受投票的功能请求之一。
- 更新了管理 Timescale 的混合行-列存储 (hypercore) 的方法。这些方法突出了列存储的使用。列存储包括优化的列式格式以及压缩。
我们对 SQL 助手进行了一些改进
专用 SQL 助手线程 🧵
现在每个查询、笔记本和仪表板都有自己的对话线程,使您的聊天井井有条。
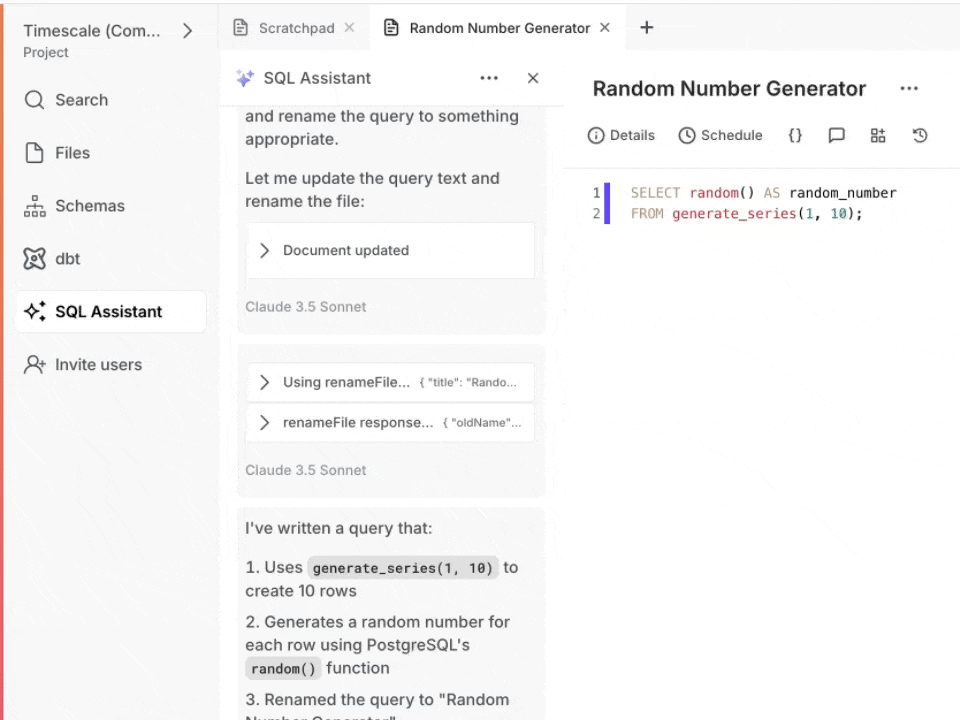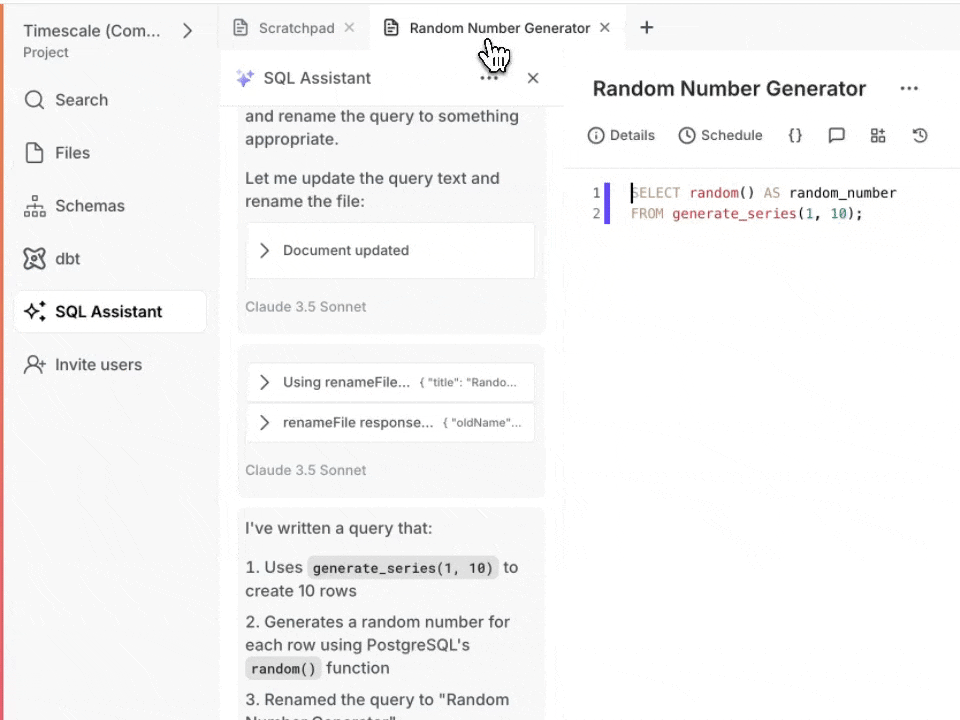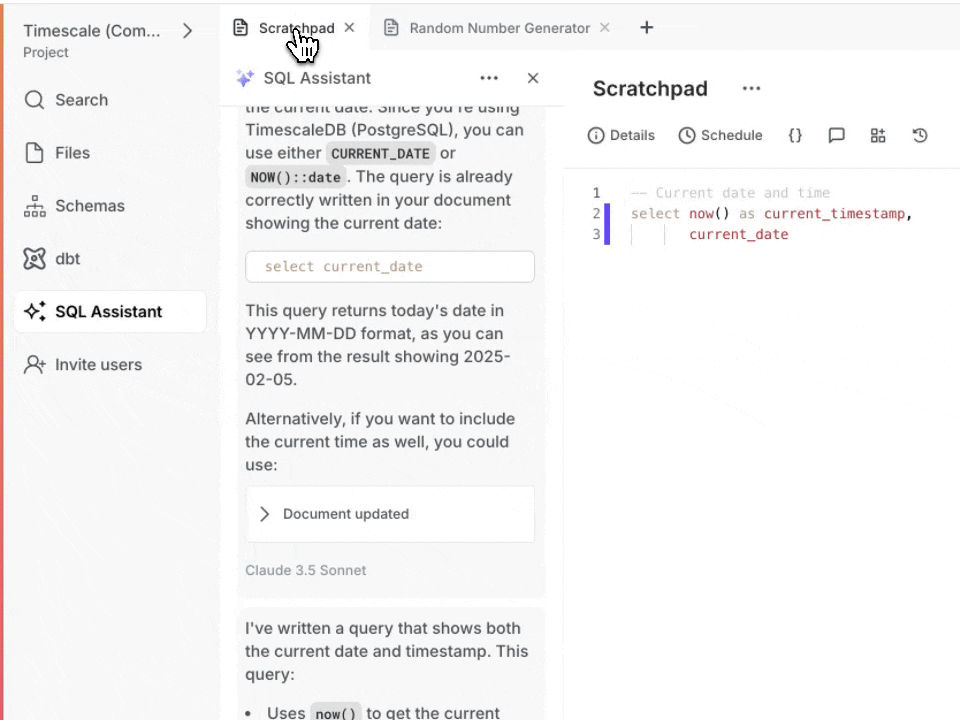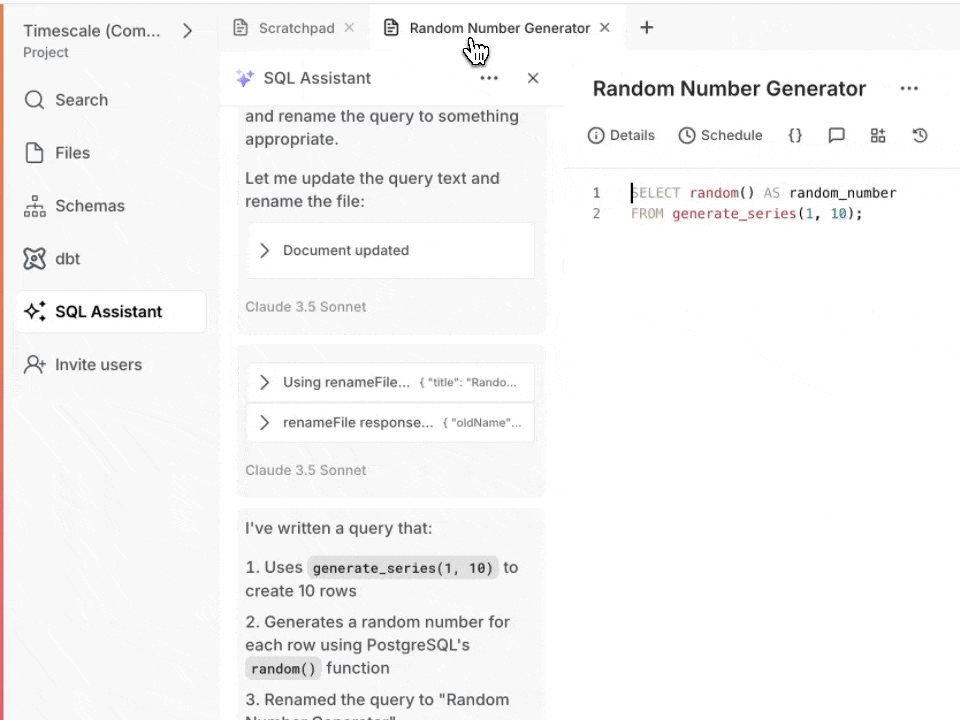
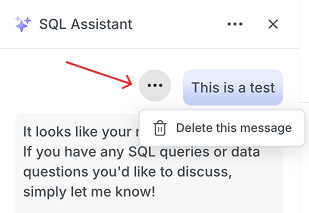
删除消息 ❌
输错字了吗?问错了问题?您现在可以从线程中删除单个消息,以保持对话的清晰和相关性。
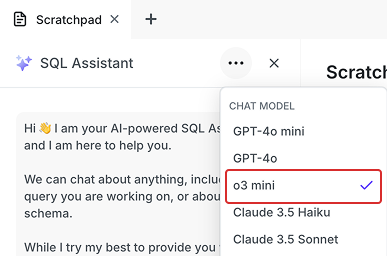
支持 OpenAI o3-mini ⚡
我们添加了对 OpenAI 最新的 o3-mini 模型的支持,为 SQL 查询带来了更快的响应时间和改进的推理能力。
为了增强网络安全性,您现在还可以在 Timescale Console 数据模式和 PopSQL 中创建 IP 允许列表。与操作模式 IP 允许列表类似,此功能仅允许某些 IP 地址访问您的数据。例如,您可能要求您的员工使用 VPN,并将您的 VPN 静态出口 IP 添加到允许列表。
此功能在以下位置可用
- Timescale Console 数据模式,适用于所有定价层级
- PopSQL Web 版
- PopSQL 桌面版
在 PopSQL/Timescale Console 数据模式中启用此功能 > Project > Settings > IP Allowlist
此版本通过为 OpenAI API 添加可配置的 base_url 支持来增强 Vectorizer 功能。这使得 pgai Vectorizer 能够通过简单地更改 base_url,通过 OpenAI 集成使用所有与 OpenAI 兼容的模型和 API。此版本还包括矢量化器的公共授权、在任何表上创建超级用户、Ollama 客户端升级到 0.4.5、新的 docker-start 命令,以及针对结构处理、模式限定和系统包管理的各种修复。在 Github 上查看所有更改。
此版本为向量嵌入添加了全面的 SQLAlchemy 和 Alembic 支持,包括迁移操作和改进的模型继承模式。您现在可以将向量搜索功能与 SQLAlchemy 模型无缝集成,同时利用 Alembic 进行数据库迁移。此版本还为 Ollama 集成和自托管 Vectorizer 配置添加了关键改进。在 Github 上查看所有更改。
2025 年 1 月 17 日Timescale Cloud 现在允许您通过 AWS Transit Gateway 连接到您的 Timescale Cloud 服务。此功能适用于 Scale 和 Enterprise 客户。它将在早期访问阶段持续一小段时间,并很快在 Timescale Console 中提供。如果您有兴趣实施此早期访问功能,请联系您的代表。
2025 年 1 月 10 日Timescale Cloud 现在支持孟买区域。从今天开始,您可以在孟买运行 Timescale Cloud 服务,将我们的数据库解决方案更贴近印度的用户。
Timescale Cloud 服务现在可以直接从版本 14、15 或 16 升级到 PostgreSQL 17。运行版本 12 或 13 的用户必须先升级到版本 15 或 16,然后才能升级到 17。
Timescale Cloud 现在在 AWS Marketplace 上可用。这允许您将账单集中在您的 AWS 账户上,使用您已承诺的 AWS 企业折扣计划支出支付您的 Timescale Cloud 账单,并简化采购和供应商管理。
2024 年 12 月 20 日所有新的 Timescale Cloud 服务现在都配备了最新的 Postgres 17.2 版本。对于运行先前版本的服务,Postgres 17 的升级将在 1 月份提供。Postgres 17 为 Timescale 增加了新功能和改进,例如
- 系统级性能改进。显著的性能提升,尤其是在高并发工作负载中。I/O 层的增强功能,包括改进的预写日志 (WAL) 处理,可以在重负载下将写入吞吐量提高高达 2 倍。
- 增强的 JSON 支持。新的 JSON_TABLE 允许开发人员将 JSON 数据直接转换为关系表,从而简化 JSON 和 SQL 的集成。此版本还添加了新的 SQL/JSON 构造函数和查询函数,提供了强大的工具来在传统关系模式中操作和查询 JSON 数据。
- 更灵活的 MERGE 操作。MERGE 命令现在包含 RETURNING 子句,使其更易于跟踪和处理修改后的数据。您现在还可以使用 MERGE 更新视图,为复杂的查询和数据操作解锁新的用例。
您现在可以直接从控制台提交功能请求,并查看您已提出的功能请求列表。只需单击右侧边栏上的 Feature Requests。所有功能请求都会自动发布到 Timescale 论坛,并由产品团队审核,从而提高其状态的可见性和透明度,并允许其他客户为其投票。
我们构建了一个新的解决方案,可帮助您将所有或部分 Postgres 表持续复制到 Timescale Cloud 中。
Livesync 允许您将当前的 Postgres 实例(如 RDS)作为您的主数据库,并轻松地将您的实时分析查询卸载到 Timescale Cloud,以提高其性能。如果您有任何问题或反馈,请在 Timescale Community 中的 #livesync 中与我们交流。
这仅仅是开始——您将在 2025 年看到更多来自 Livesync 的内容!
2024 年 12 月 13 日连接您的 S3 存储桶以将数据导入 Timescale Cloud。在此初始版本中,我们支持 CSV(包括 .zip 和 .gzip)和 Parquet 文件,文件大小限制为 10 GB。此功能在服务创建后立即在 导入您的数据 部分以及通过 操作 选项卡访问。
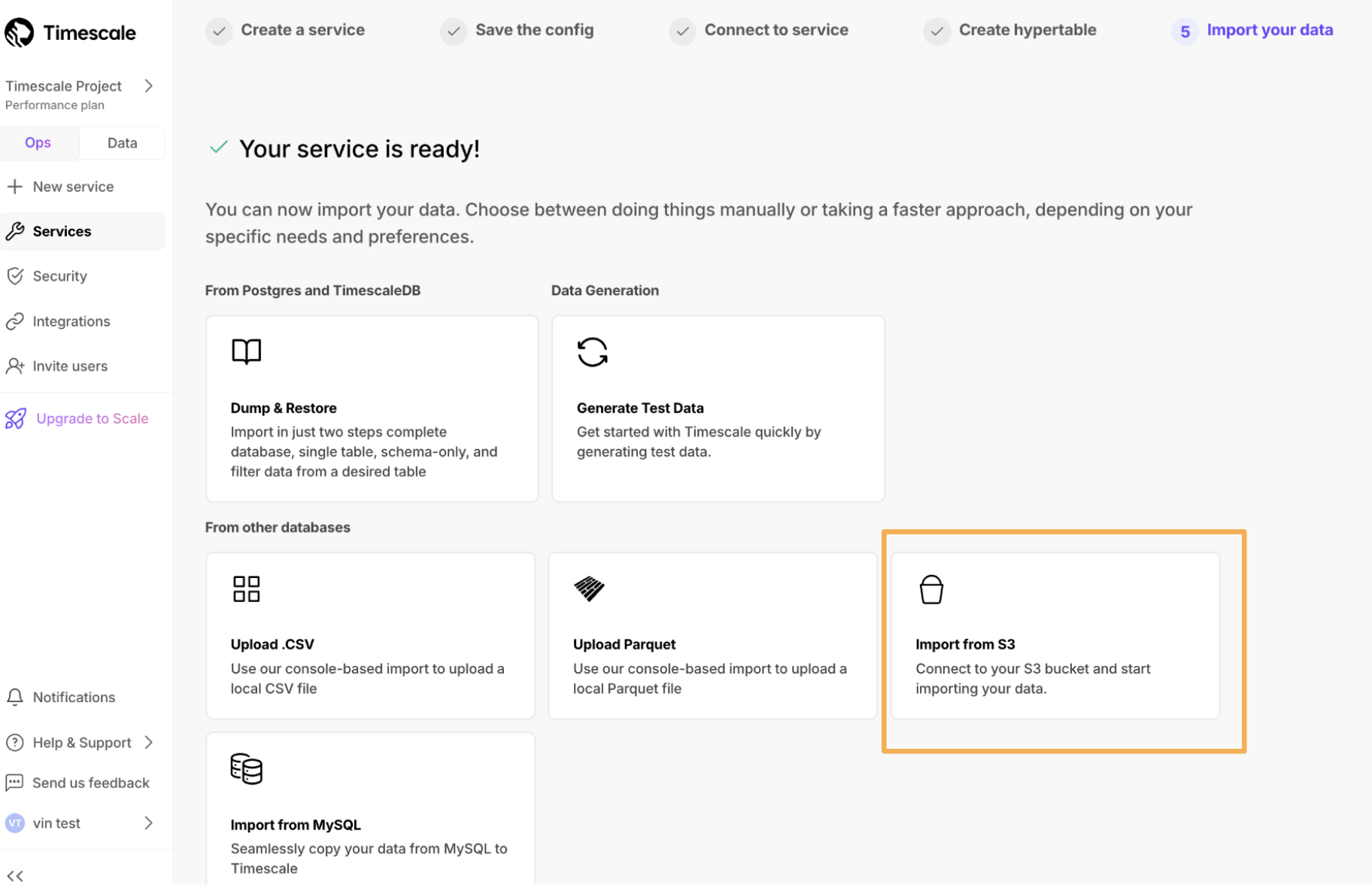
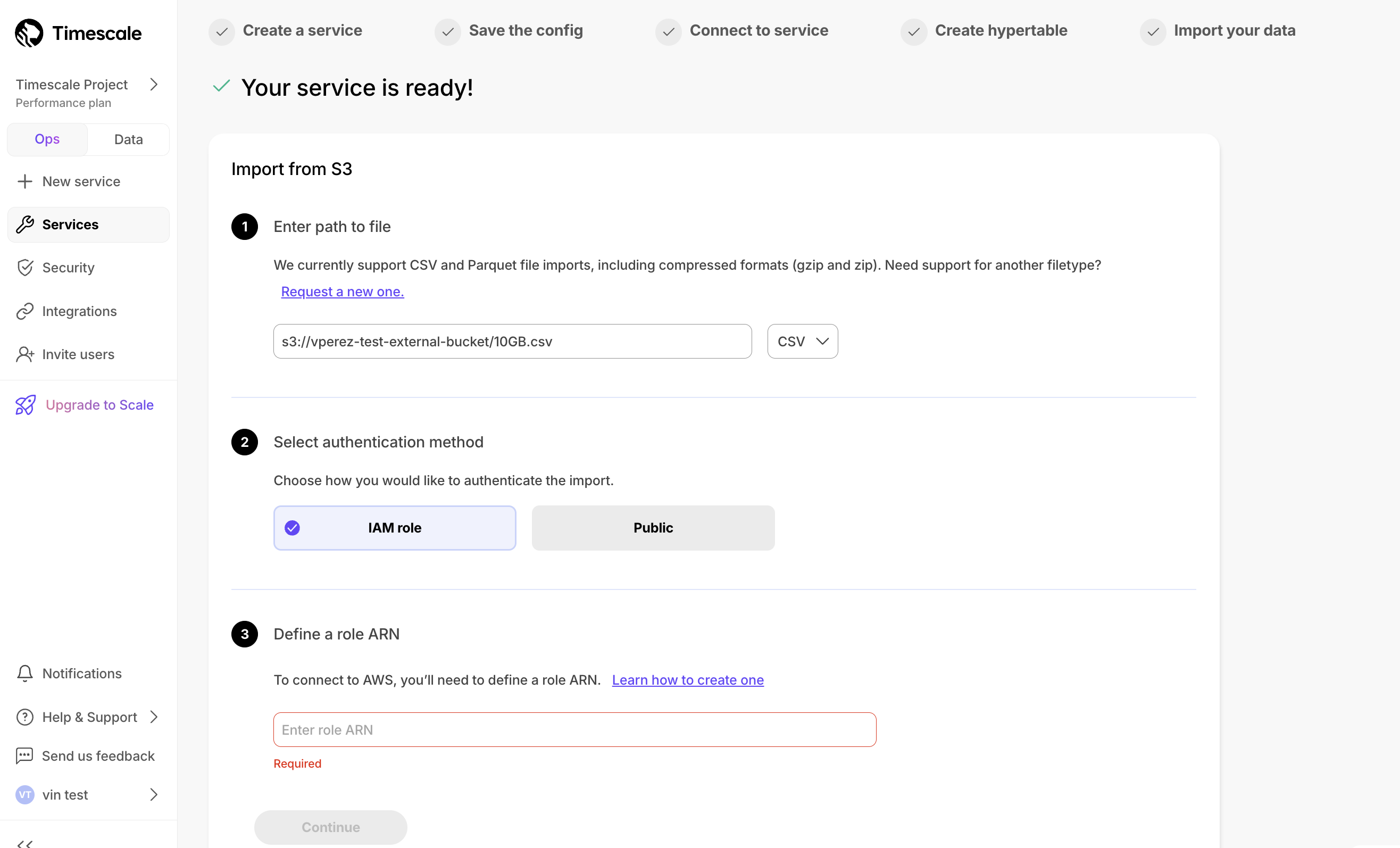
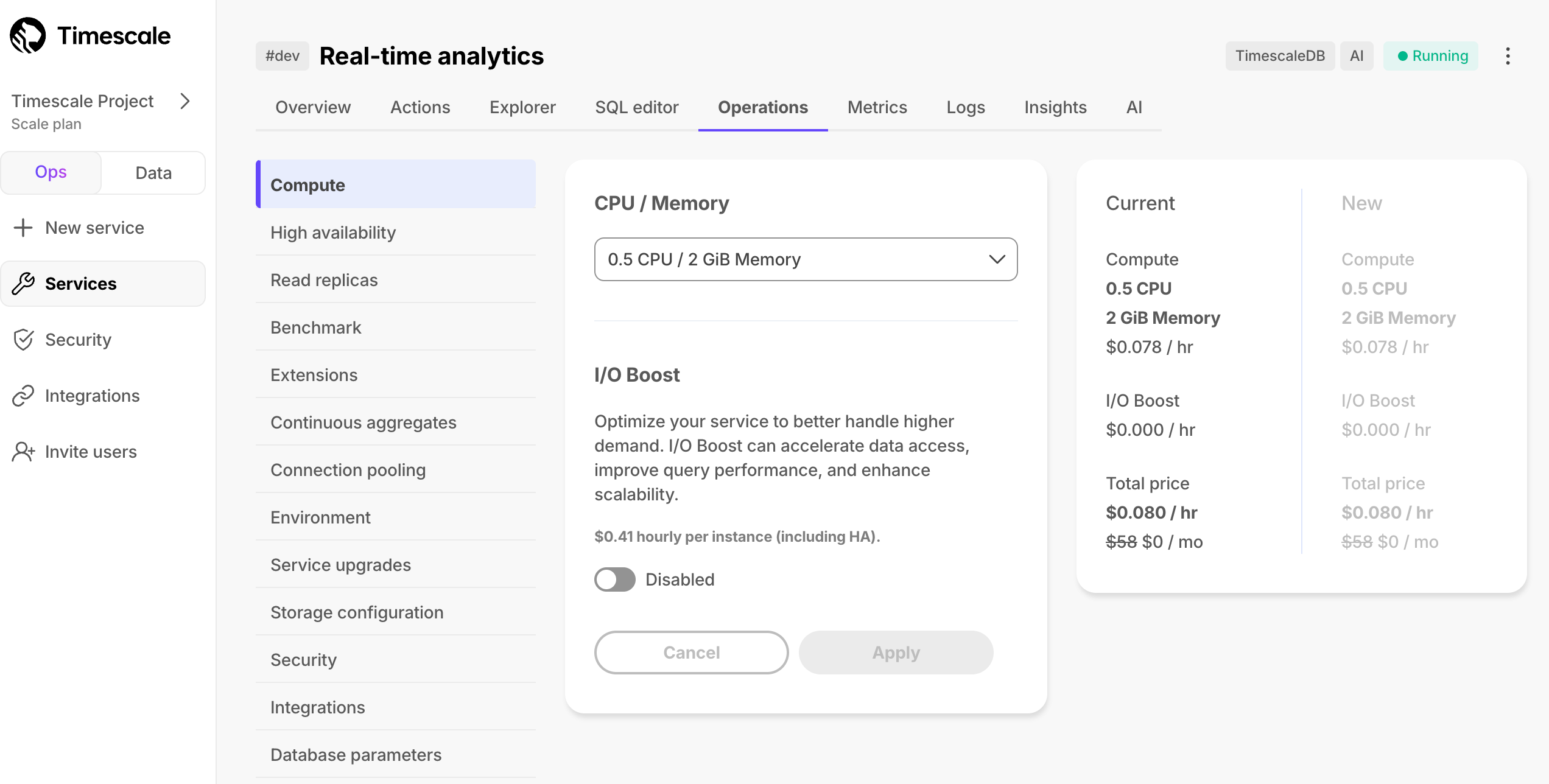
I/O 提升是面向 Scale 或 Enterprise 层级客户的附加组件,可将 EBS 存储的 I/O 容量最大化到每个服务 16,000 IOPS 和 1,000 MBps 吞吐量。要启用 I/O 提升,请导航到 Timescale Console 中的 服务 > 操作。一个简单的开关允许您启用该功能,价格清楚地显示为每个节点每小时 0.41 美元。
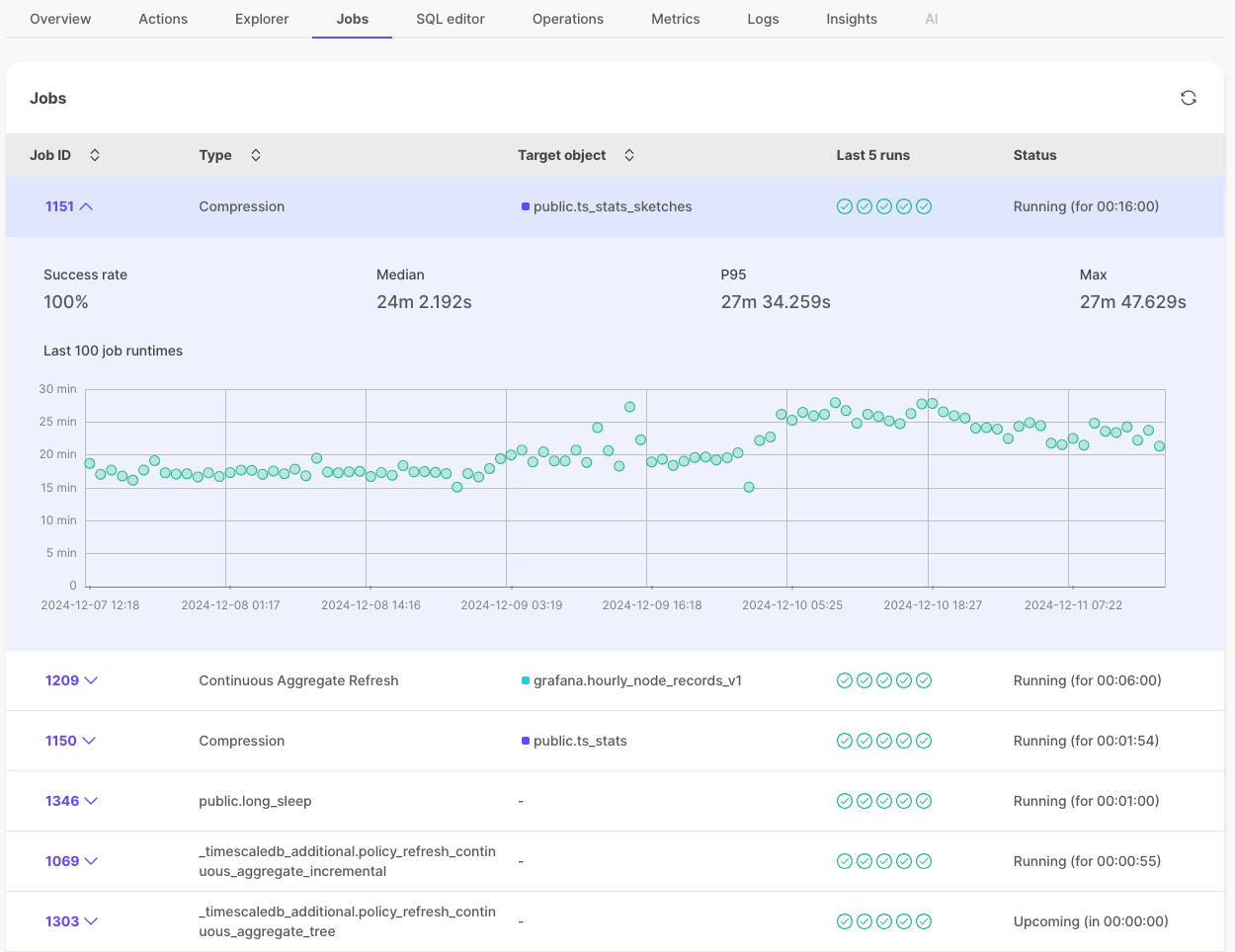
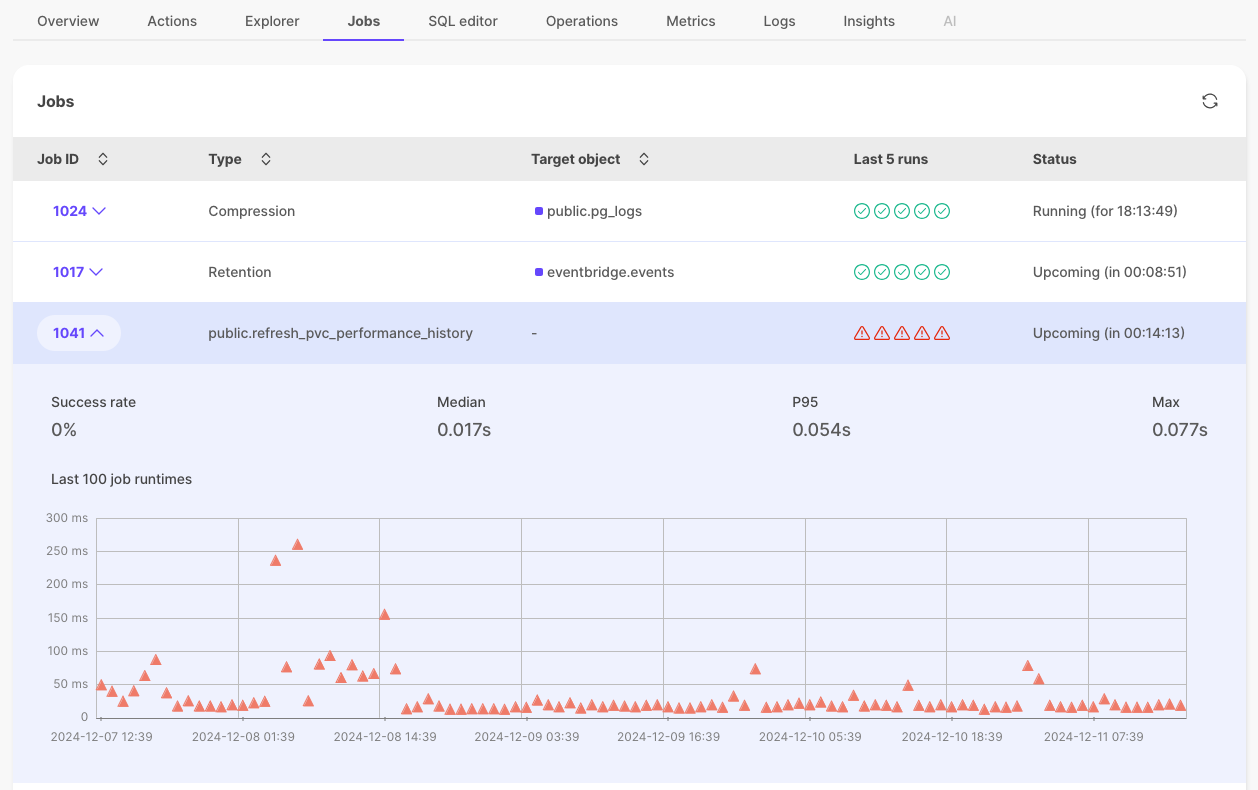
通过新的 作业 选项卡查看与您的服务关联的所有作业。您可以查看作业类型、其状态(运行中、已暂停 等)以及最近 100 次运行的详细历史记录,包括成功率和运行时统计信息。
AI 和向量: UI 现在允许您从一开始就选择创建 AI 和向量就绪服务的选项。您不再需要手动添加 pgai、pgvector 和 pgvectorscale 扩展。您也可以将此与时序功能结合使用!
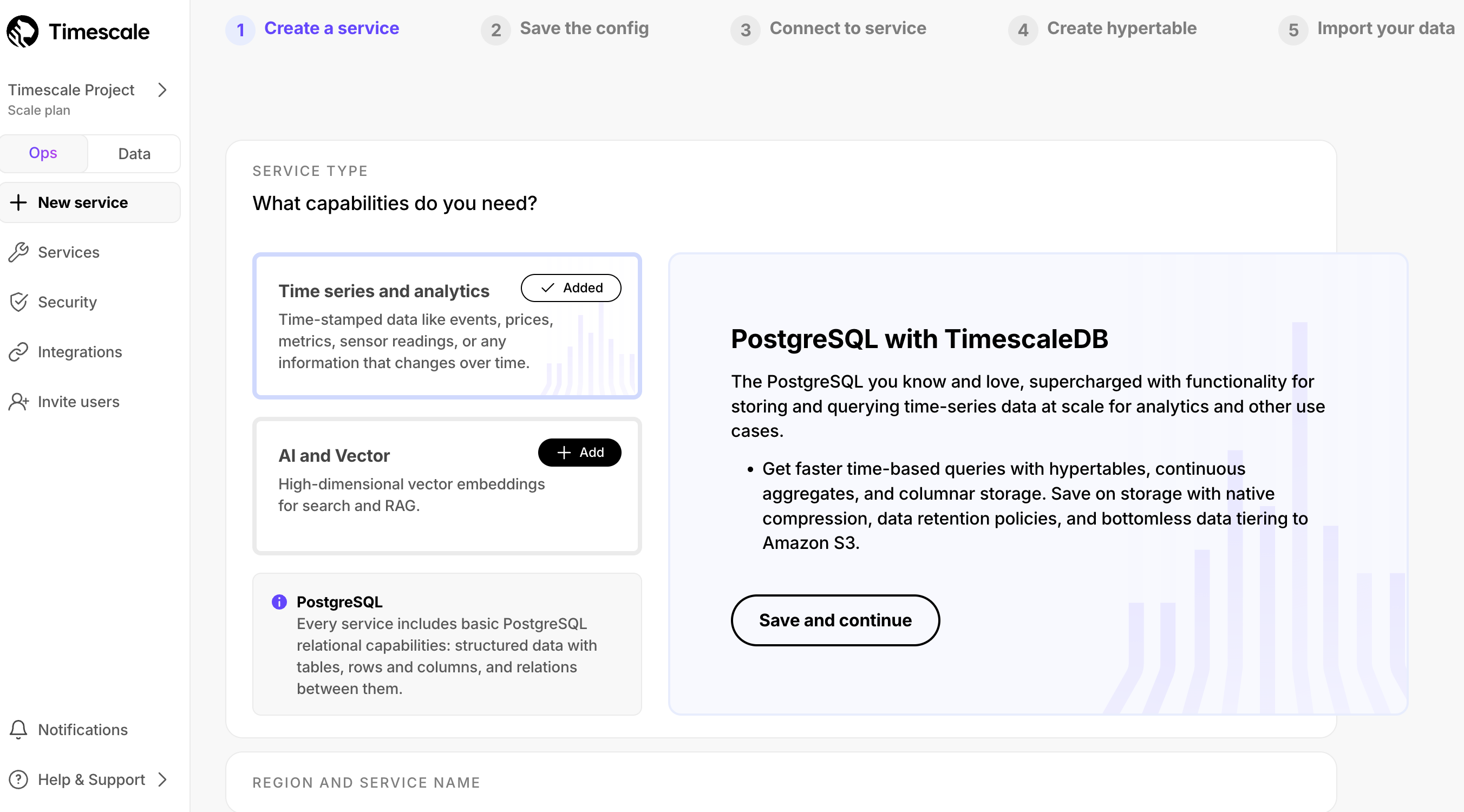
计算大小建议: 新(和旧)用户有时不确定为其工作负载使用多大的计算大小。我们现在根据您计划在服务中拥有多少数据提供计算大小建议。
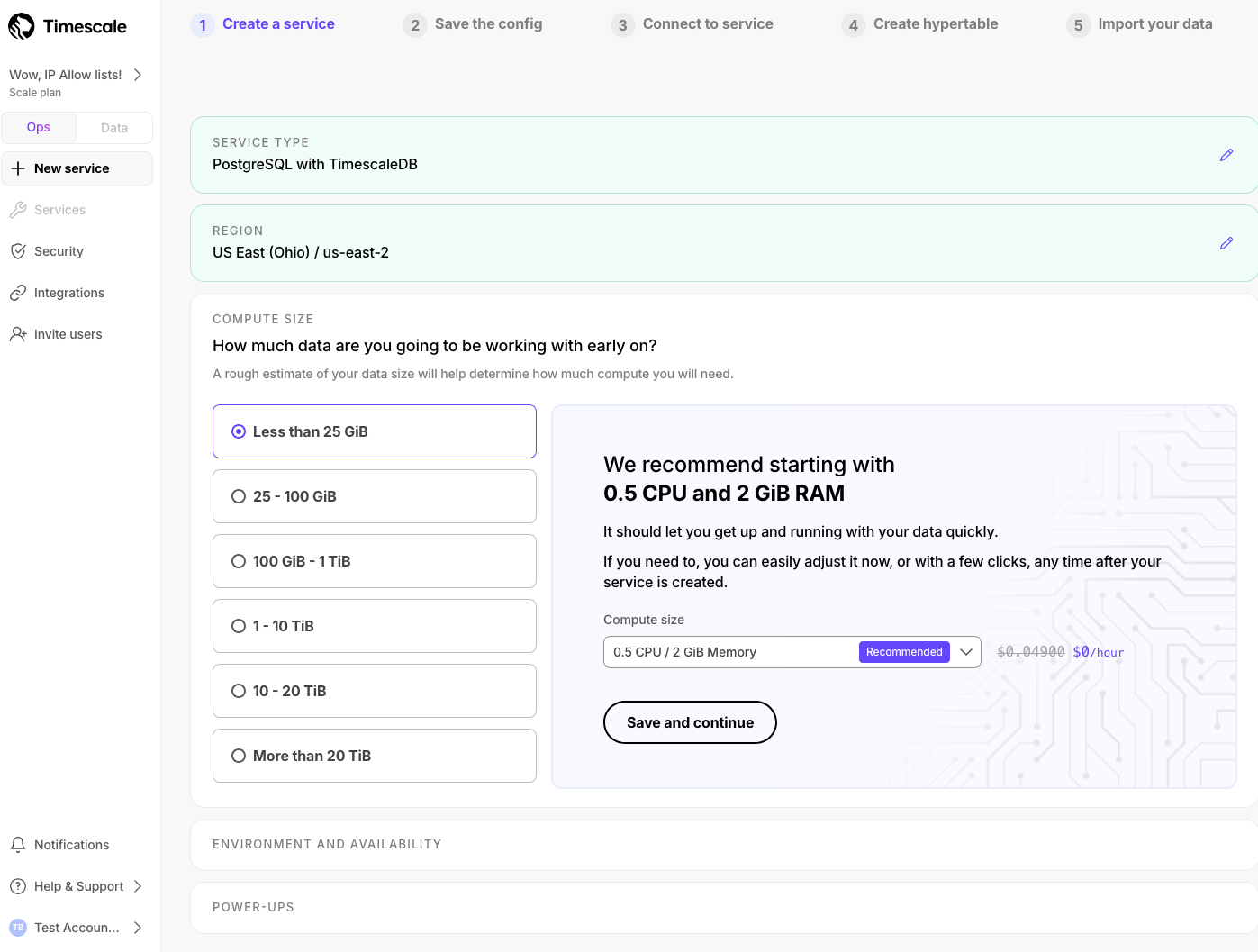
有关配置选项的更多信息: 我们已经更清楚地说明了每个配置选项的作用,以便您可以就如何设置服务做出更明智的选择。
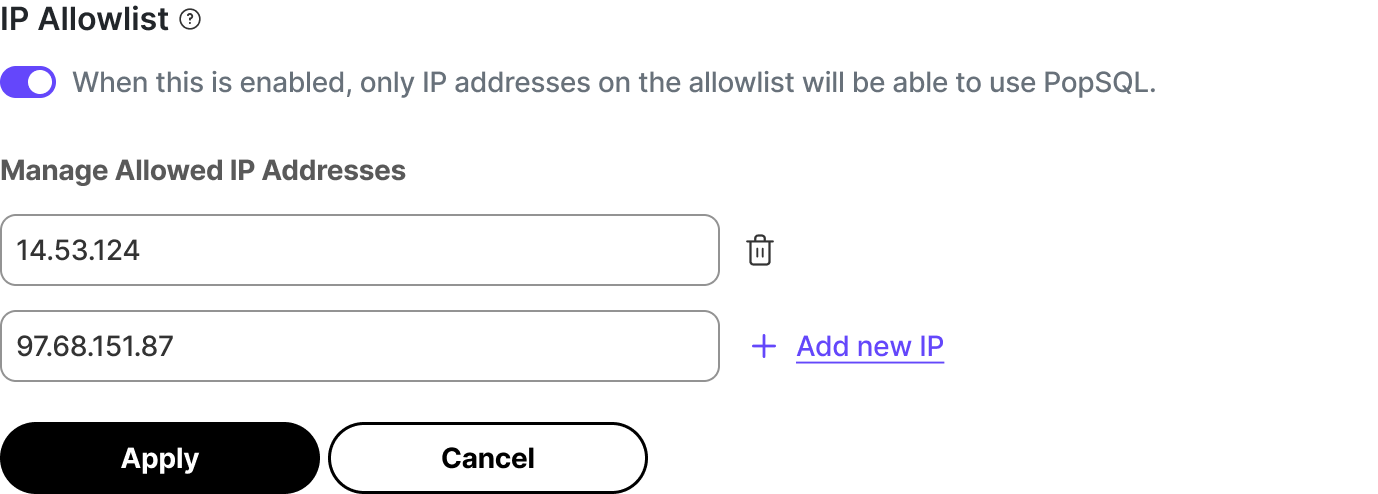
IP 允许列表允许您指定有权访问您的 Timescale Cloud 服务的 IP 地址列表,并阻止任何其他地址。对于关注安全性和合规性的客户而言,IP 允许列表是一种轻量但有效的解决方案。它们使您无需 虚拟私有云 (VPC) 即可防止未经授权的连接。
要开始使用,请在 Timescale Console 中,选择一项服务,然后单击 操作 > 安全 > IP 允许列表,然后创建 IP 允许列表。
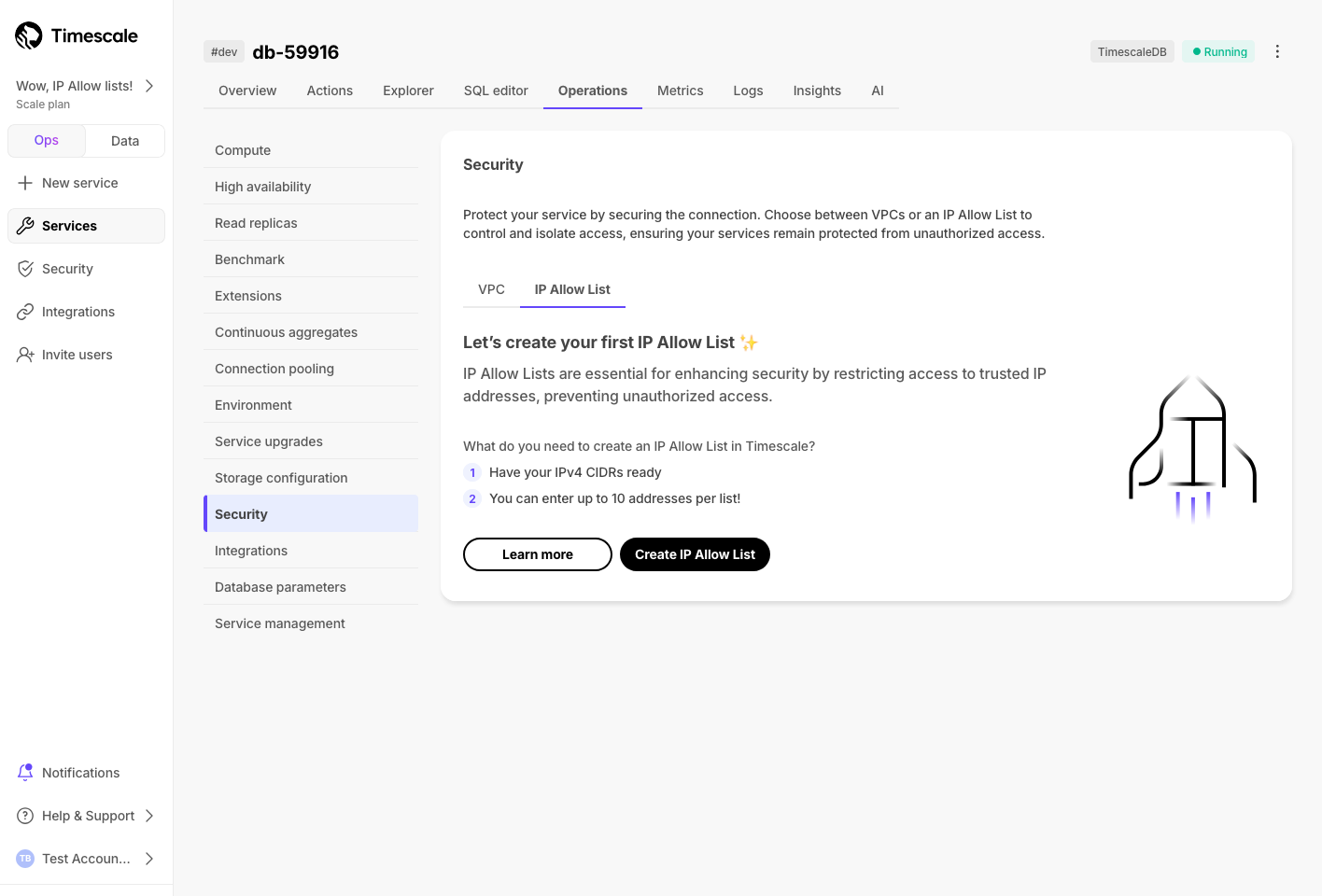
有关更多信息,请参阅我们的文档。
2024 年 11 月 14 日SQL 助手使用 AI 帮助您更快、更准确地编写 SQL。
实时帮助: 与 OpenAI 4o 和 Claude 3.5 Sonnet 等模型聊天,以获得编写 SQL 的帮助。用自然语言描述您想要的内容,让 AI 为您编写 SQL。
错误解决:当您遇到错误时,SQL 助手会提出建议的修复方案,您可以选择接受。
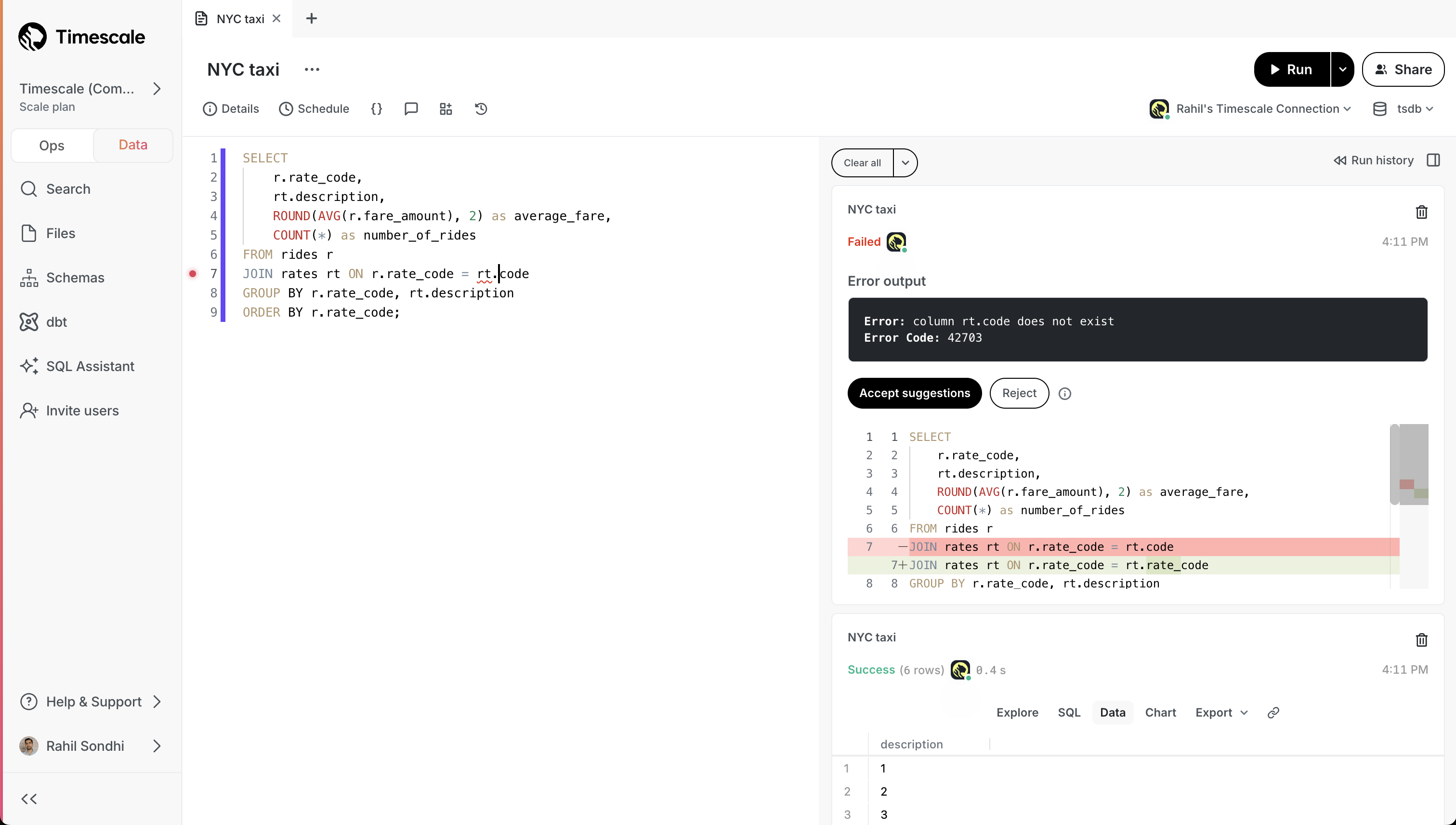
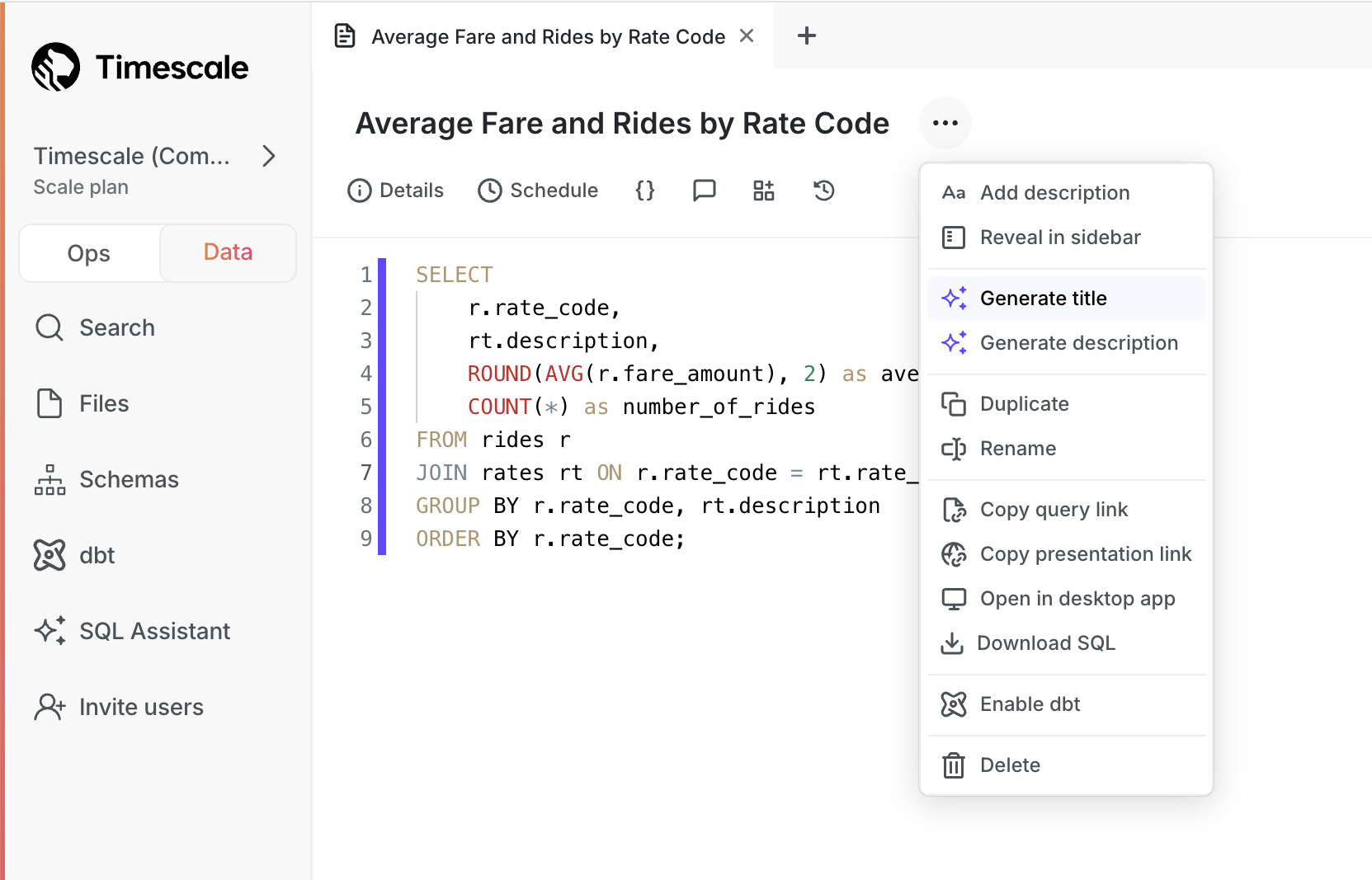
生成标题和描述:单击按钮,SQL 助手会为您的查询生成标题和描述。不再有无标题的查询!
从本周开始,在 Timescale Cloud 上创建的所有新服务都使用 TimescaleDB v2.17。现有服务将在其维护窗口期间逐步升级。
TimescaleDB v2.17 显著提高了 连续聚合刷新的性能,并包含了针对压缩超表上的分析查询和删除操作的性能改进。
最佳实践是在下次可用时机升级。
TimescaleDB v2.17 中的突出功能是
连续聚合策略的显著性能改进
连续聚合刷新现在使用
merge而不是删除旧的物化数据并重新插入。连续聚合策略现在更轻量级,使用更少的系统资源,并且完成速度更快。此更新
- 在存在少量更改的情况下,大幅减少了必须在连续聚合上写入的数据量
- 降低了刷新连续聚合的 i/o 成本
- 生成更少的预写日志 (
WAL)
提高了压缩超表上实时分析查询的性能
我们很高兴为 TimescaleDB 引入额外的单指令多数据 (SIMD) 向量化优化。此版本支持对使用
segment_by列进行分组,以及使用sum、count、avg、min和max基本聚合函数进行聚合的查询进行向量化执行。请继续关注后续版本中的更多内容!对在其他列上分组、过滤聚合、向量化表达式和
time_bucket的支持即将推出。改进了在压缩超表上删除大量数据时的性能。
此改进通过跳过解压缩步骤来加速删除整个段的操作。它适用于所有按
segment_by列进行过滤的删除操作。
Timescale Cloud 的 Enterprise 计划 现在符合 HIPAA(健康保险流通与责任法案)合规性。这允许组织安全地管理和分析敏感的医疗保健数据,确保他们在构建合规应用程序时满足监管要求。
客户现在可以访问 Timescale Console 中最近 500 条日志以外的更多日志。我们更新了用户体验,包括具有无限滚动功能的滚动条。
我们添加了有关使用您的 .NET 工作流程连接到 Timescale 的说明。在服务创建后的控制台中,或在 操作 选项卡中,您现在可以从开发人员库列表中选择 .NET。该指南演示了如何使用 Npgsql 将 Timescale 与您现有的软件堆栈集成。
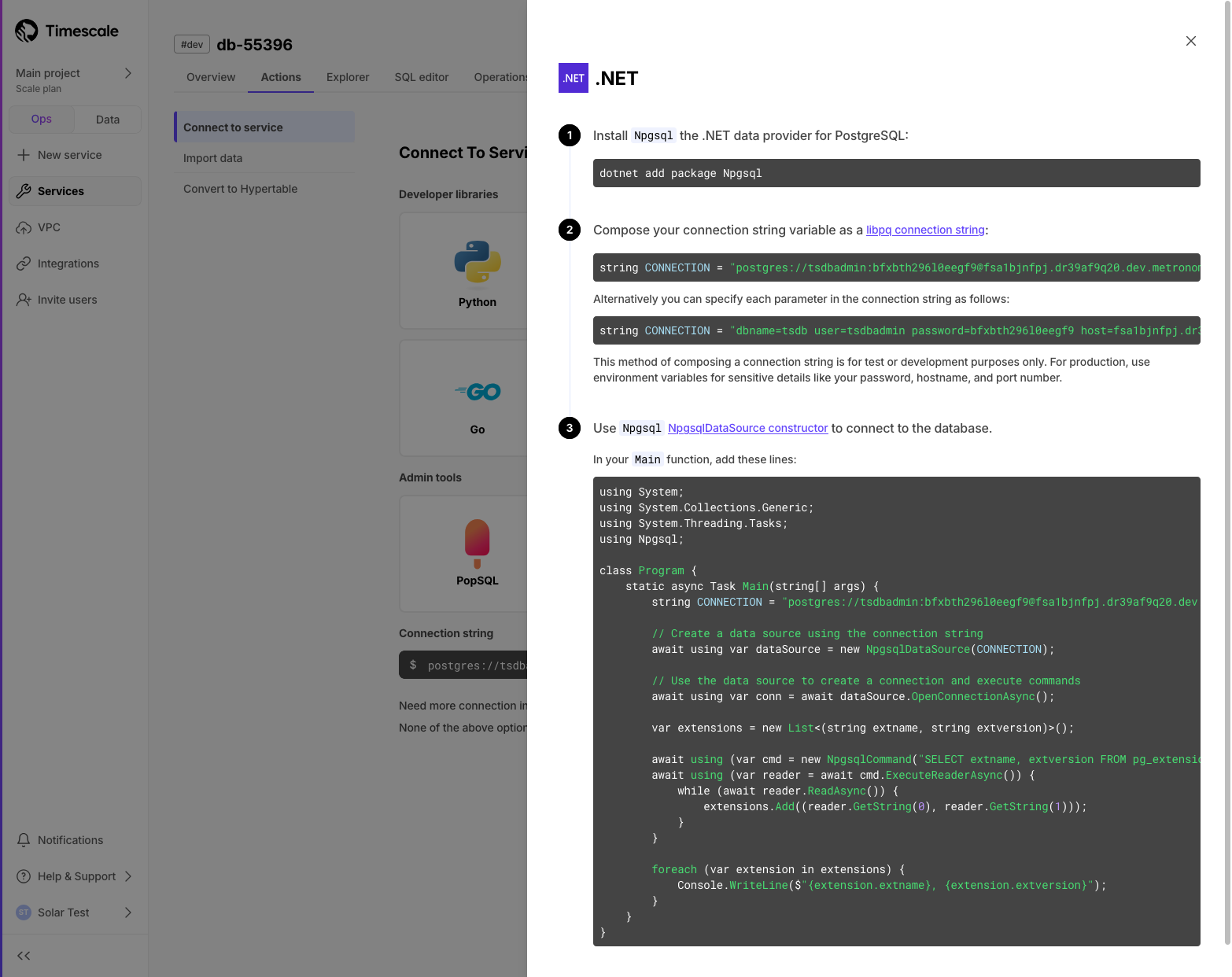
在 浏览器 的 作业 部分中,用户现在可以查看每个作业最近 5 次运行的状态(已完成/失败)。
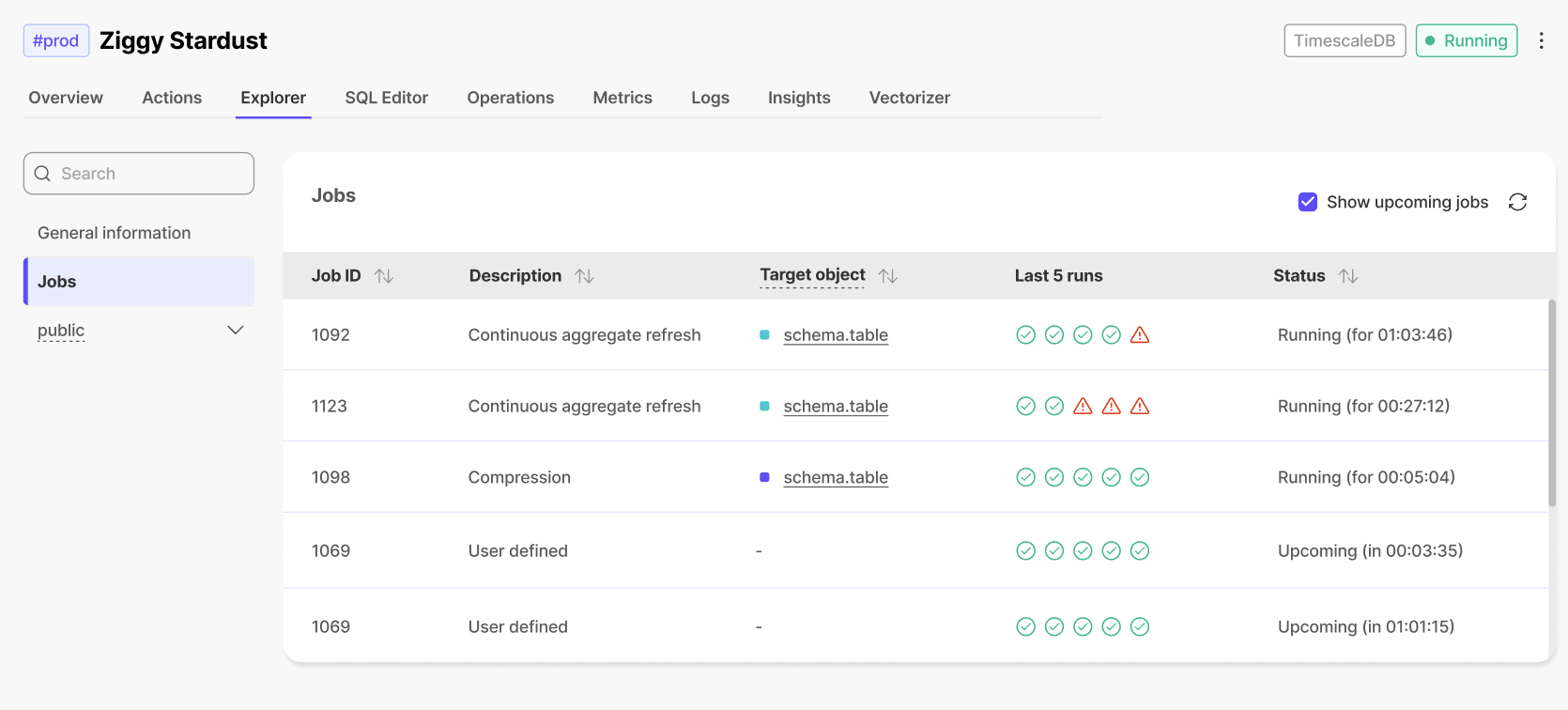
此早期访问功能使您能够随着数据的变化自动创建、更新和维护嵌入。就像索引一样,Timescale 处理所有复杂性:同步、版本控制和清理自动发生。这意味着无需手动跟踪、零维护负担,并且可以自由地快速试验不同的嵌入模型和分块策略,而无需构建新的管道。导航到服务概述中的 AI 选项卡,并按照说明添加您的 OpenAI API 密钥并设置您的第一个矢量化器,或阅读我们的 pgai Vectorizer 自动化嵌入生成指南 了解更多详情。

使用 外部数据包装器 (FDW),直接在 Timescale Cloud 中获取和查询来自多个 PostgreSQL 数据库的数据,包括超表中的时序数据。无需更复杂的 ETL 流程或外部工具——只需在您的 SQL 编辑器中进行无缝集成。此功能非常适合管理多个 PostgreSQL 和时序实例,并且需要快速、轻松地访问跨数据库数据的开发人员。
此版本增加了对运行时块排除的支持,用于需要访问 分层存储 的查询。块排除现在可以与在 WHERE 子句中使用稳定表达式的查询一起使用。这种类型查询的最常见形式是
SELECT * FROM hypertable WHERE timestamp_col > now() - '100 days'::interval
有关具有不可变/稳定/易失性过滤器的查询的更多信息,请查看我们关于 实施约束排除以获得更快的查询性能 的博客文章。
如果您不再希望为特定超表使用分层存储,您现在可以禁用分层,并通过调用 disable_tiering 函数 删除超表上关联的分层元数据。
Timescale Console 现在为超表中包含过多小块的服务显示建议。针对每个性能不佳的服务和超表,都会显示用于改进服务性能的新间隔建议。然后,用户可以在 Timescale Console 中更改其块间隔并提升性能。

创建服务后,用户现在可以直接在 Timescale Console 中创建超表,方法是先创建一个表,然后将其转换为超表。这可以使用控制台内 SQL 编辑器来实现。支持所有标准超表配置选项,以及底层表架构的任何自定义。
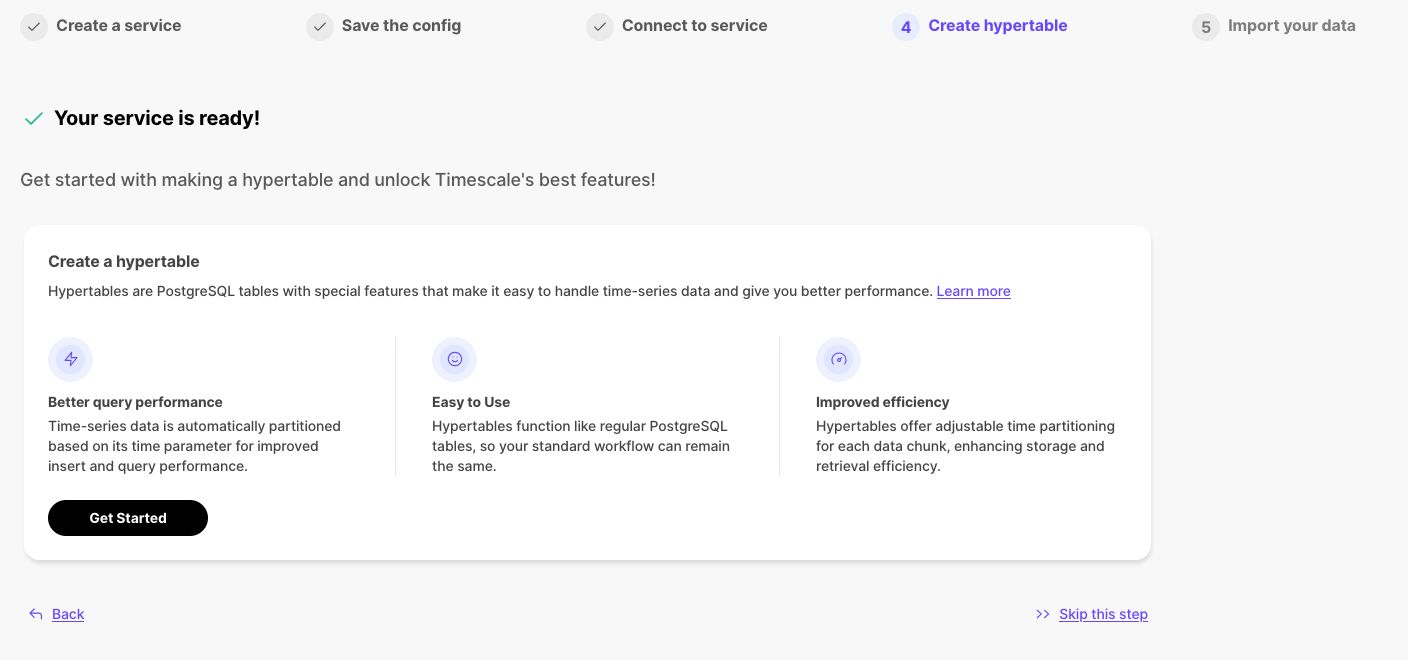
最新版本的 Data Mode Notebooks 现在速度更快。为什么?我们采用了我们新开发的 v3 查询引擎,该引擎目前为 Timescale Console 的 SQL 编辑器提供支持。查看查询响应时间的差异。
2024 年 10 月 10 日去年,我们开始开发从 PostgreSQL 和 TimescaleDB 进行低停机迁移的解决方案。从那时起,此解决方案得到了显著发展,具有增强的功能、改进的可靠性和性能优化。我们现在自豪地宣布,随着 1.0 版本的发布,实时迁移已准备好投入生产。
我们的许多客户已使用 实时迁移 成功地将数据库迁移到 Timescale,其中一些数据库的大小达到几 TB。
作为服务创建流程的一部分,我们提供以下内容
- 从不同来源连接到服务
- 从各种来源导入和迁移数据
- 创建超表
以前,这些操作仅在服务创建过程中可见,以后无法访问。现在,这些操作持久保留在服务中,允许用户在准备执行这些任务时随时利用它们。
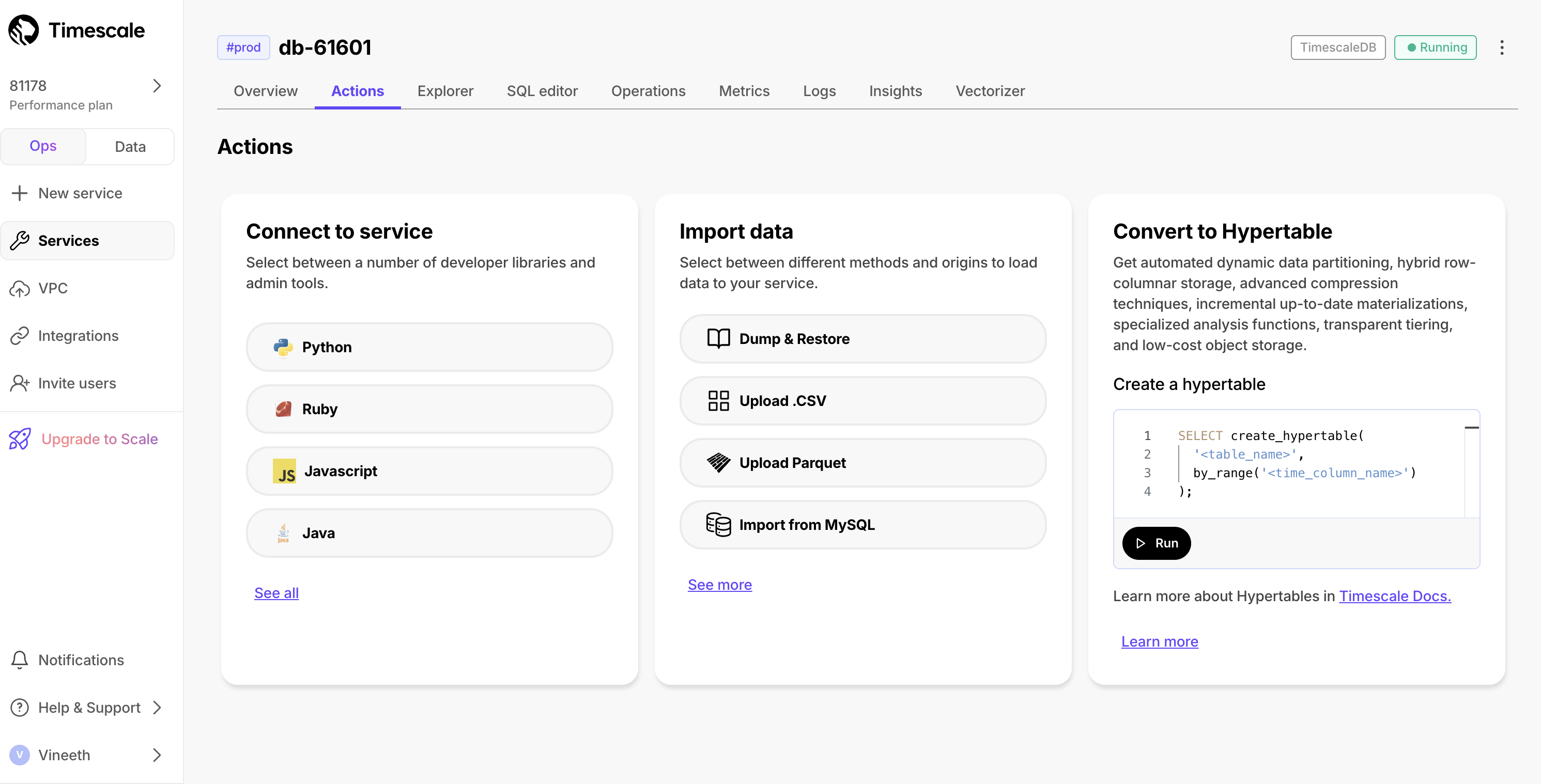
我们注意到用户在将其 MySQL 模式和数据转换为其 Timescale Cloud 服务时遇到了困难。这是由于 MySQL 和 PostgreSQL 之间的语义差异造成的。为了简化此过程,我们现在提供易于遵循的说明,用于将数据从 MySQL 导入到 Timescale Cloud。此功能在数据导入向导中作为 从 MySQL 导入 选项提供。
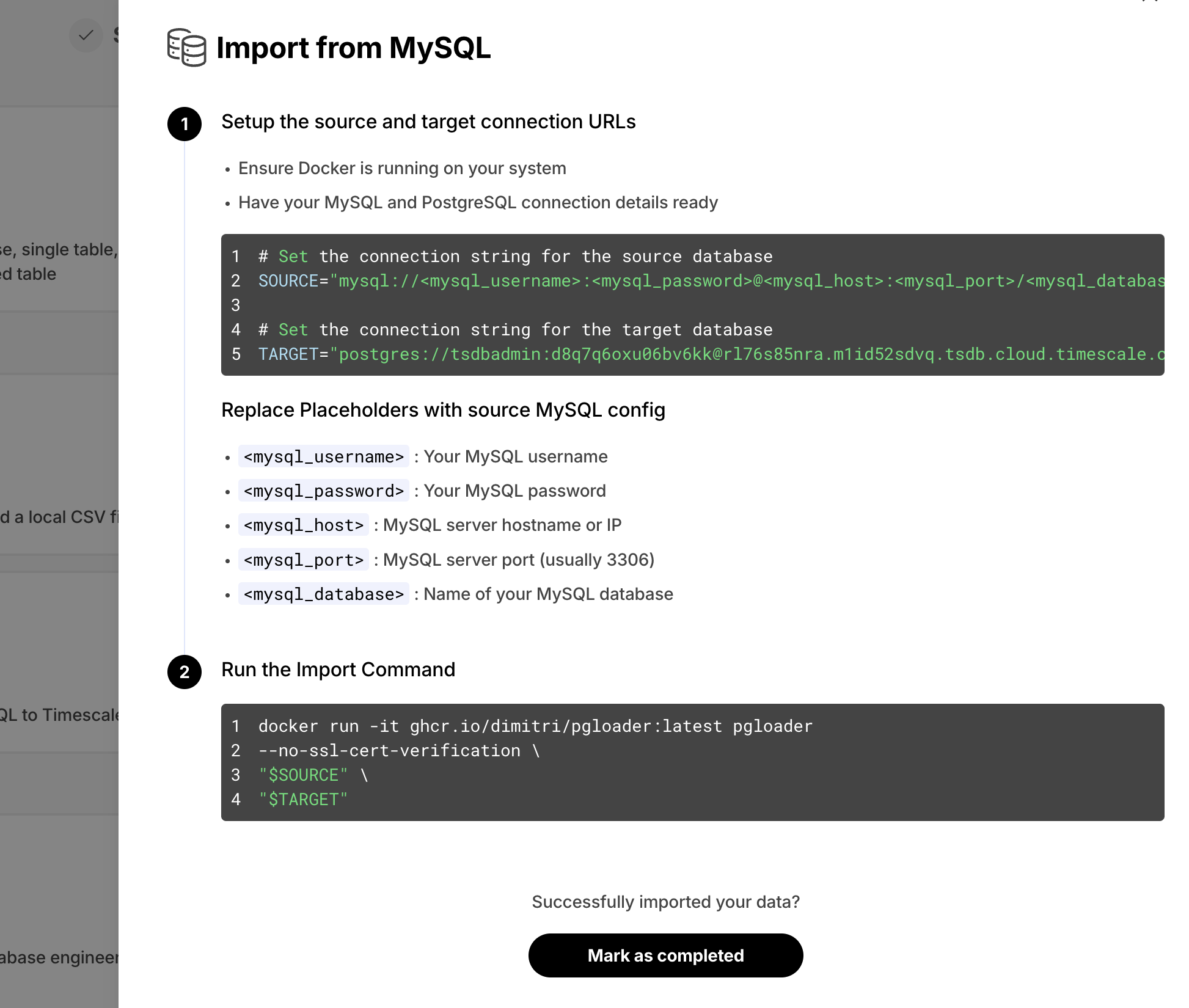
在 Timescale Console 中,我们提供 SQL 编辑器,以便您可以直接查询您的服务。作为一项新的改进,如果查询正在等待锁并且无法完成执行,Timescale Console 现在会在结果部分显示当前的锁争用。
Timescale 现在支持客户 VPC 上的多个 CIDR。想要利用多个 CIDR 的客户需要重新创建其对等连接。
2024 年 9 月 19 日我们一直在倾听您的反馈,并注意到 Timescale Console 用户有不同的需求。你们中的一些人专注于操作任务,例如添加副本或更改参数,而另一些人则深入数据分析以收集见解。
为了更好地为您服务,我们为 Timescale Console UI 引入了新模式——根据您尝试完成的任务定制体验。
操作模式是您可以管理服务、添加副本、配置压缩、更改参数等的地方。
数据模式是完整的 PopSQL 体验:编写带有自动完成功能的查询、使用图表和仪表板可视化数据、安排查询和仪表板以创建警报或定期报告、共享查询和仪表板等等。
立即试用并告诉我们您的想法!
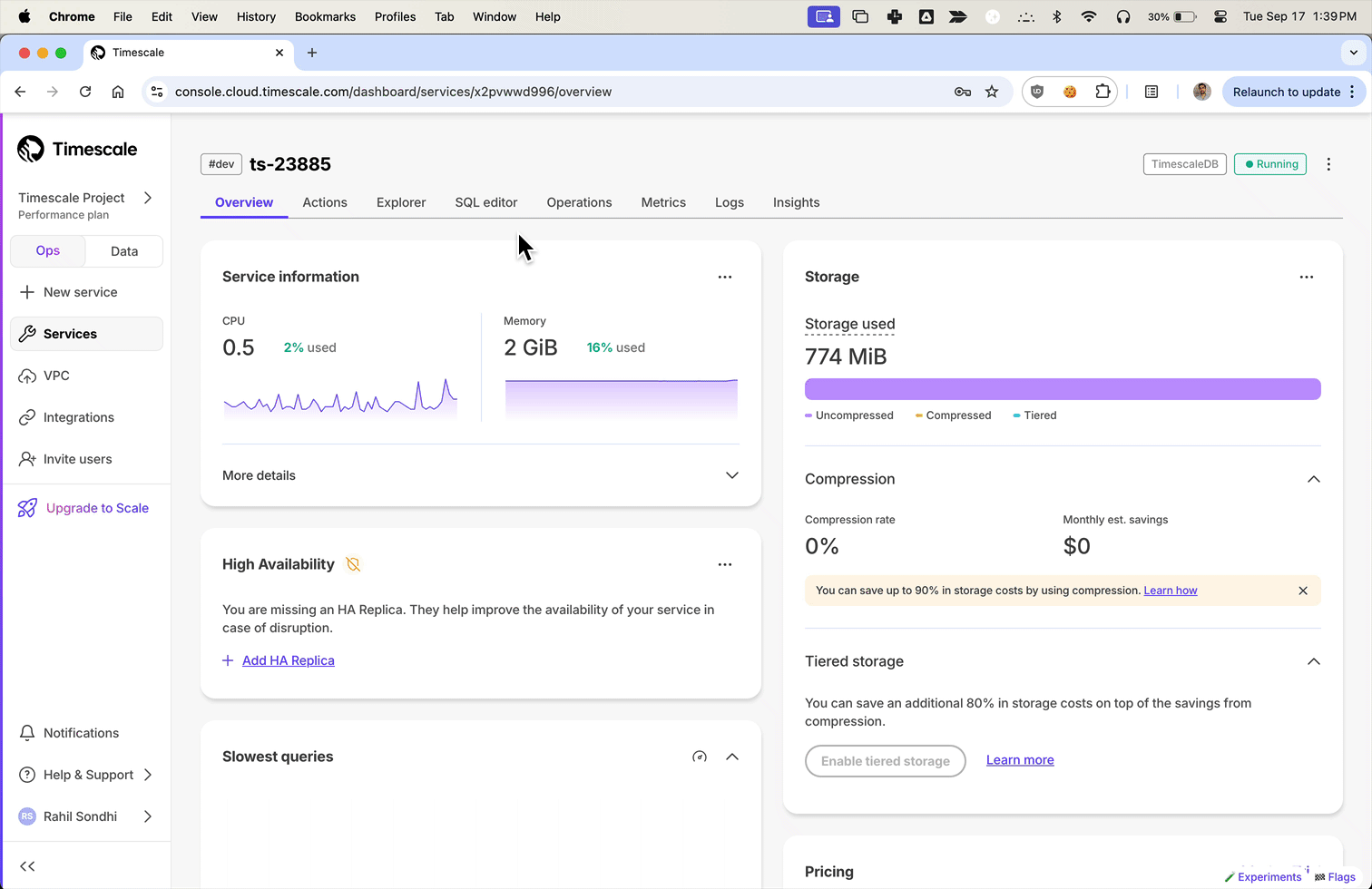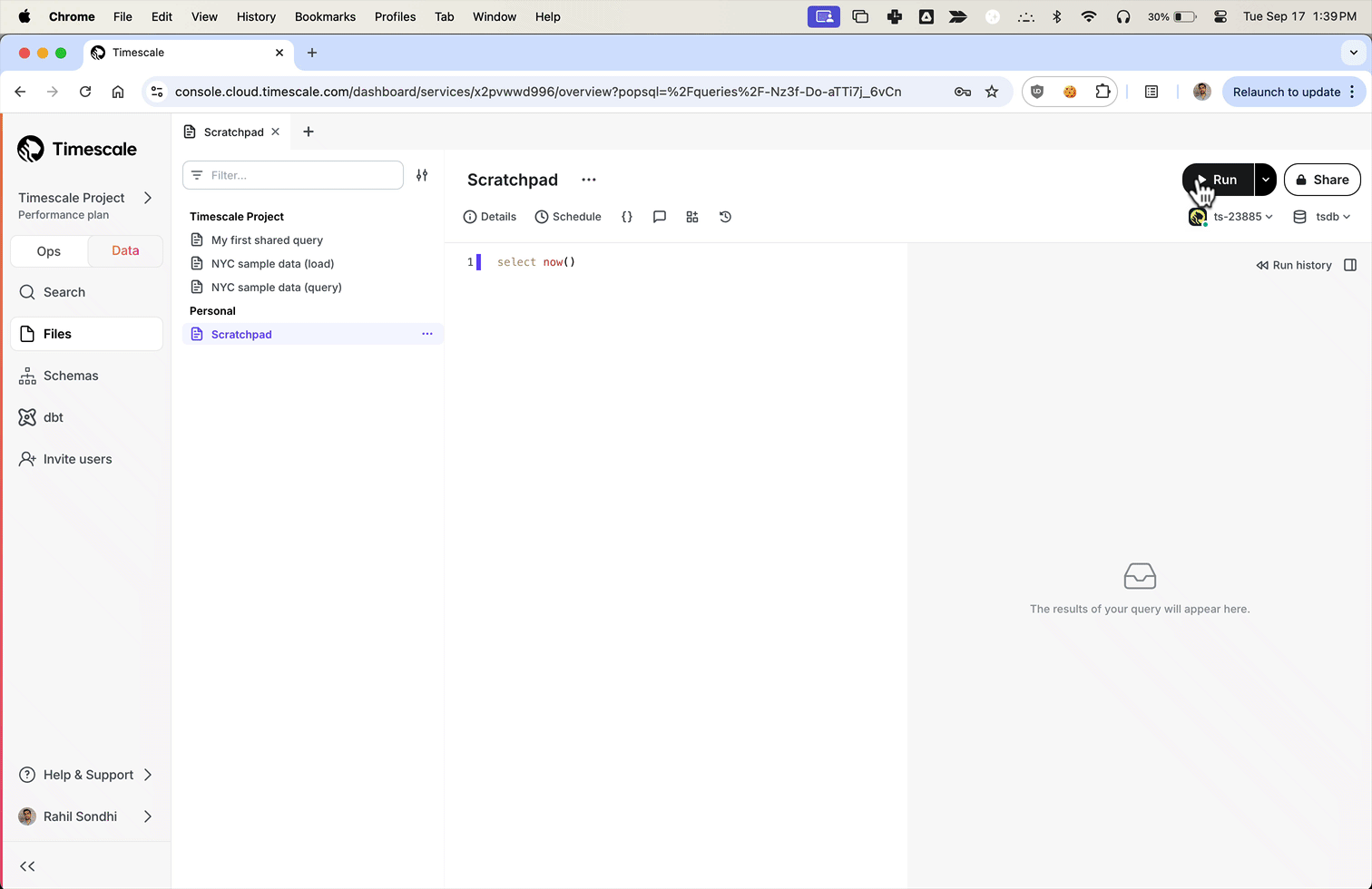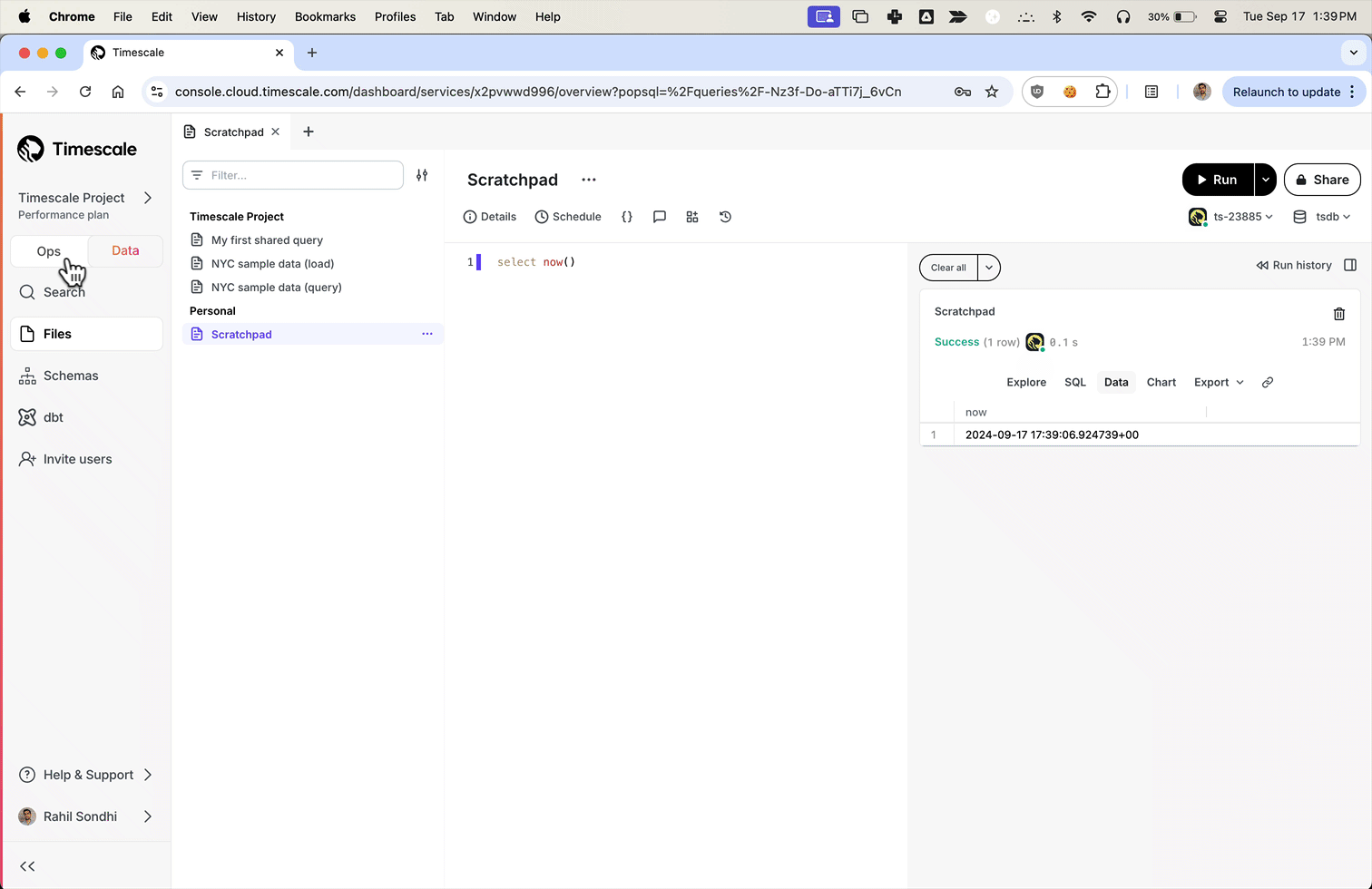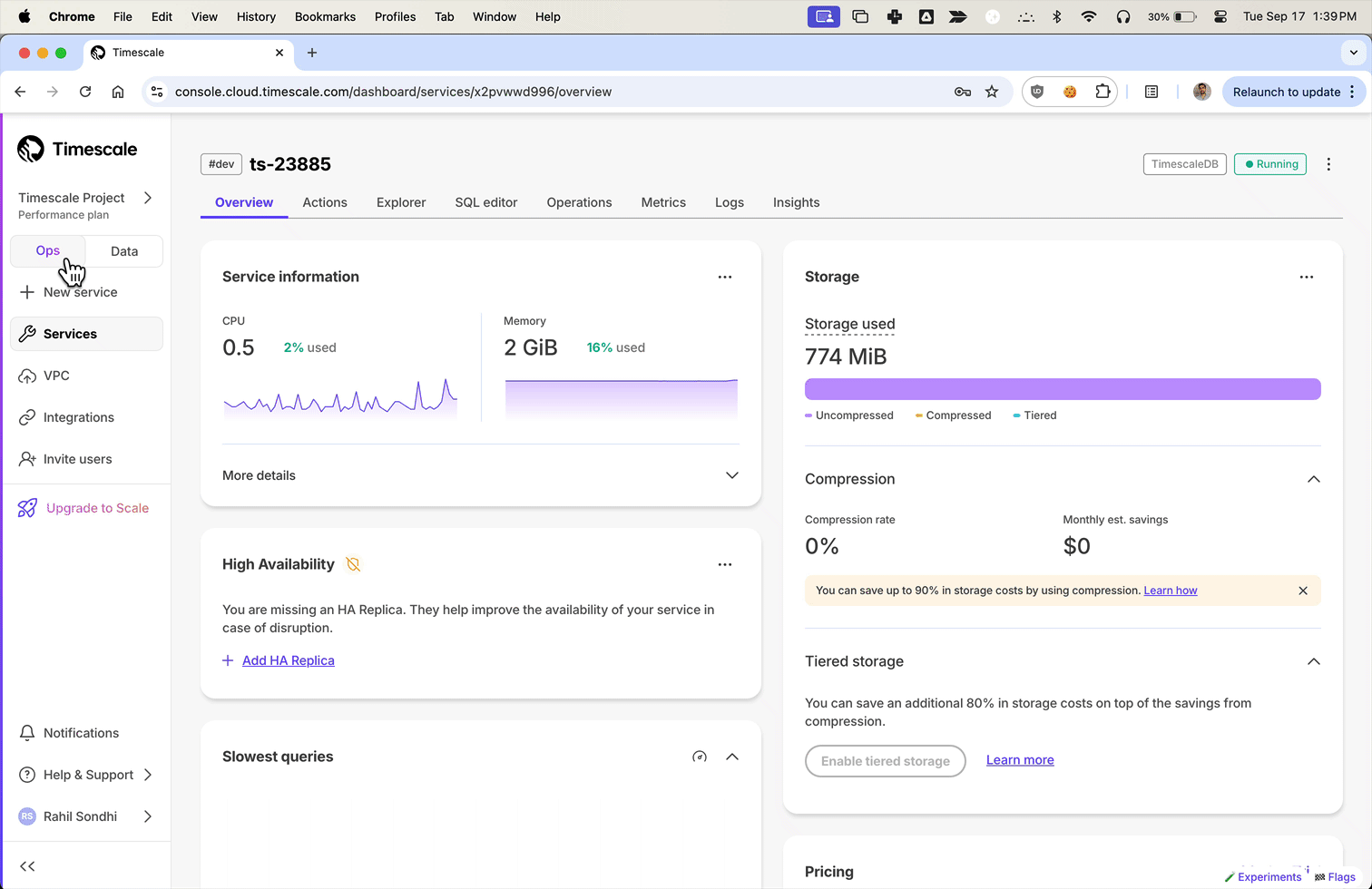
现在,用户可以通过从本地文件系统上传文件来从 Parquet 上传到 Timescale Cloud。对于大于 250 MB 的文件,或者如果您想自己完成,请按照三步流程将 Parquet 文件上传到 Timescale。
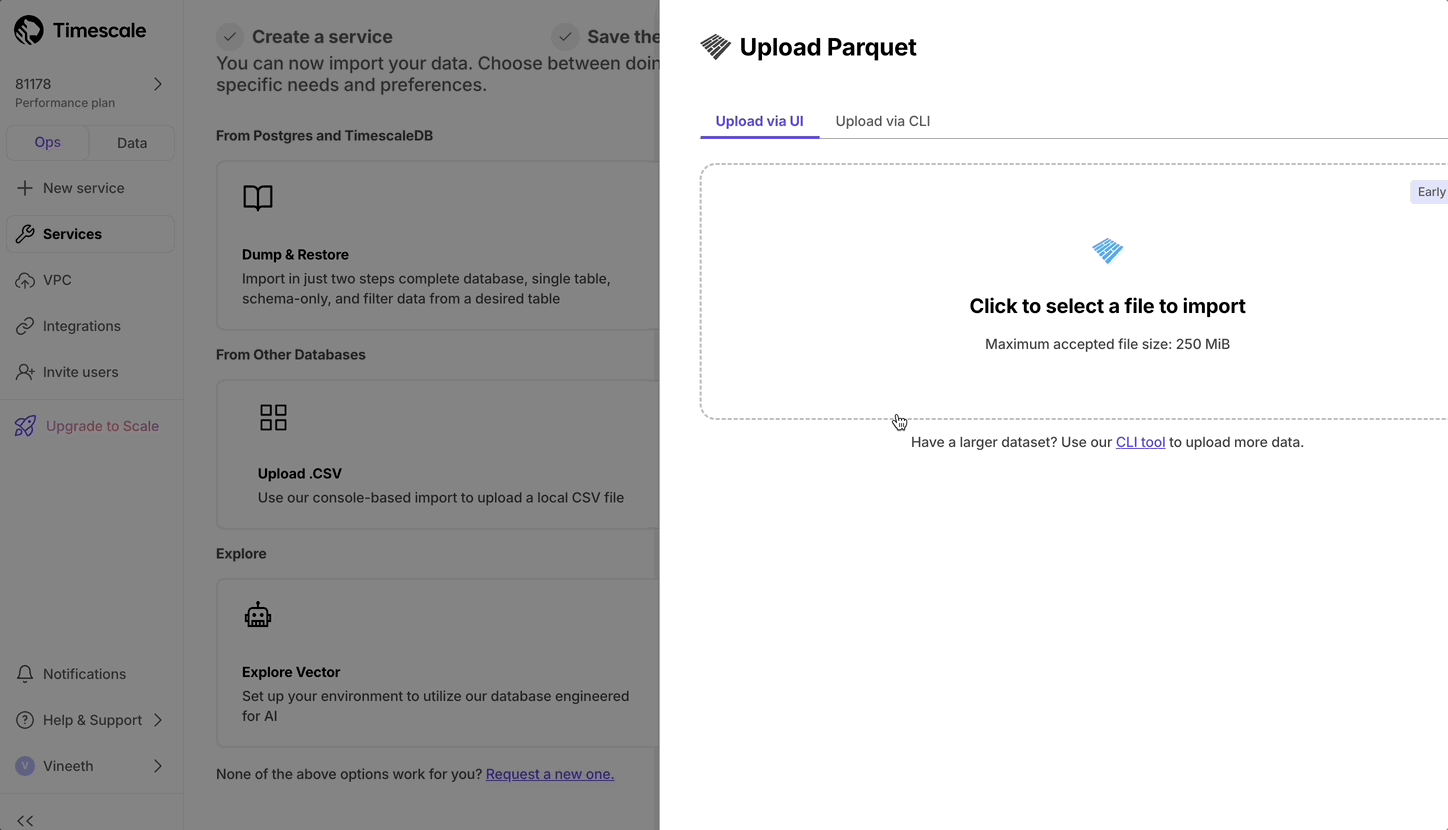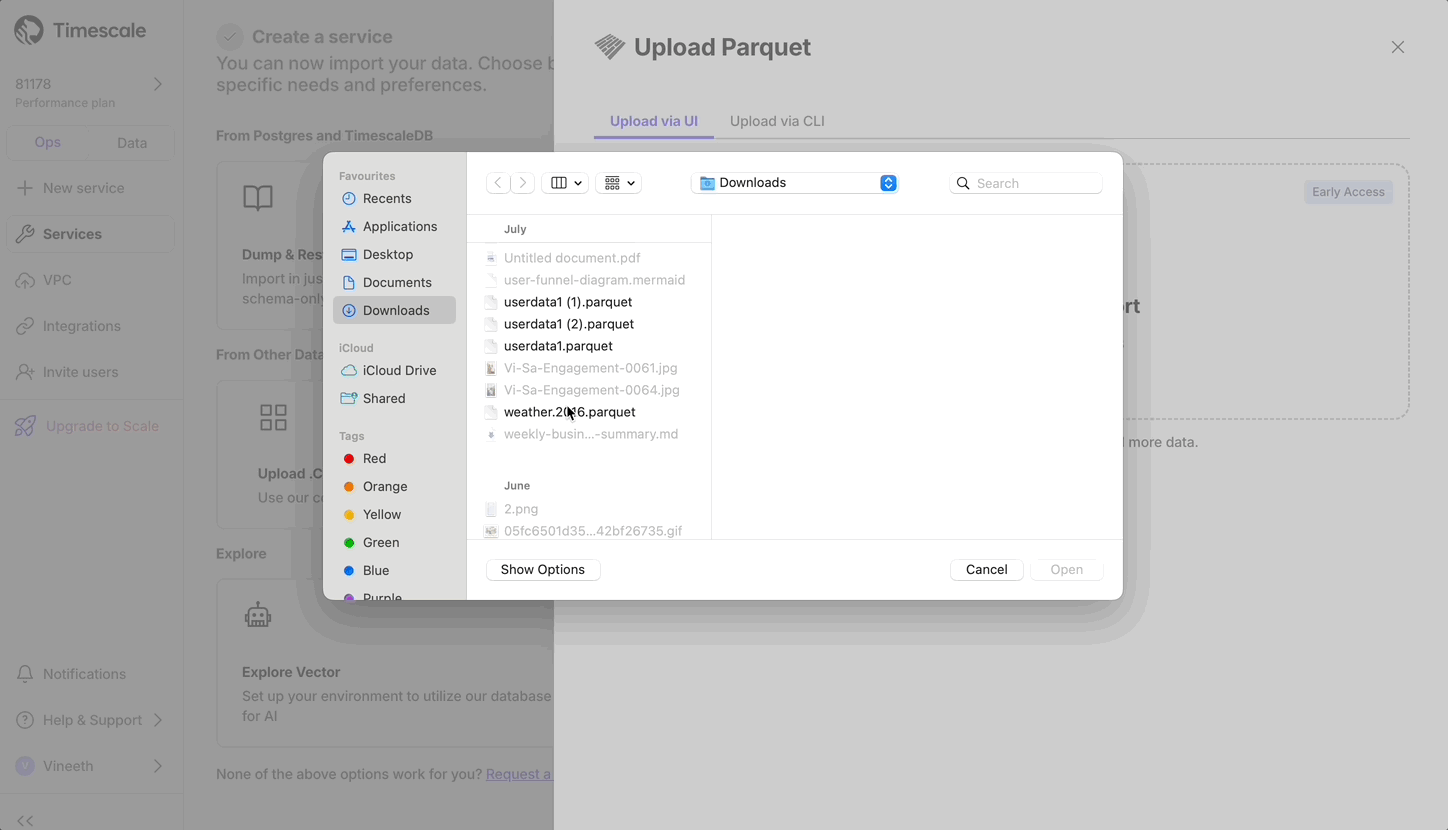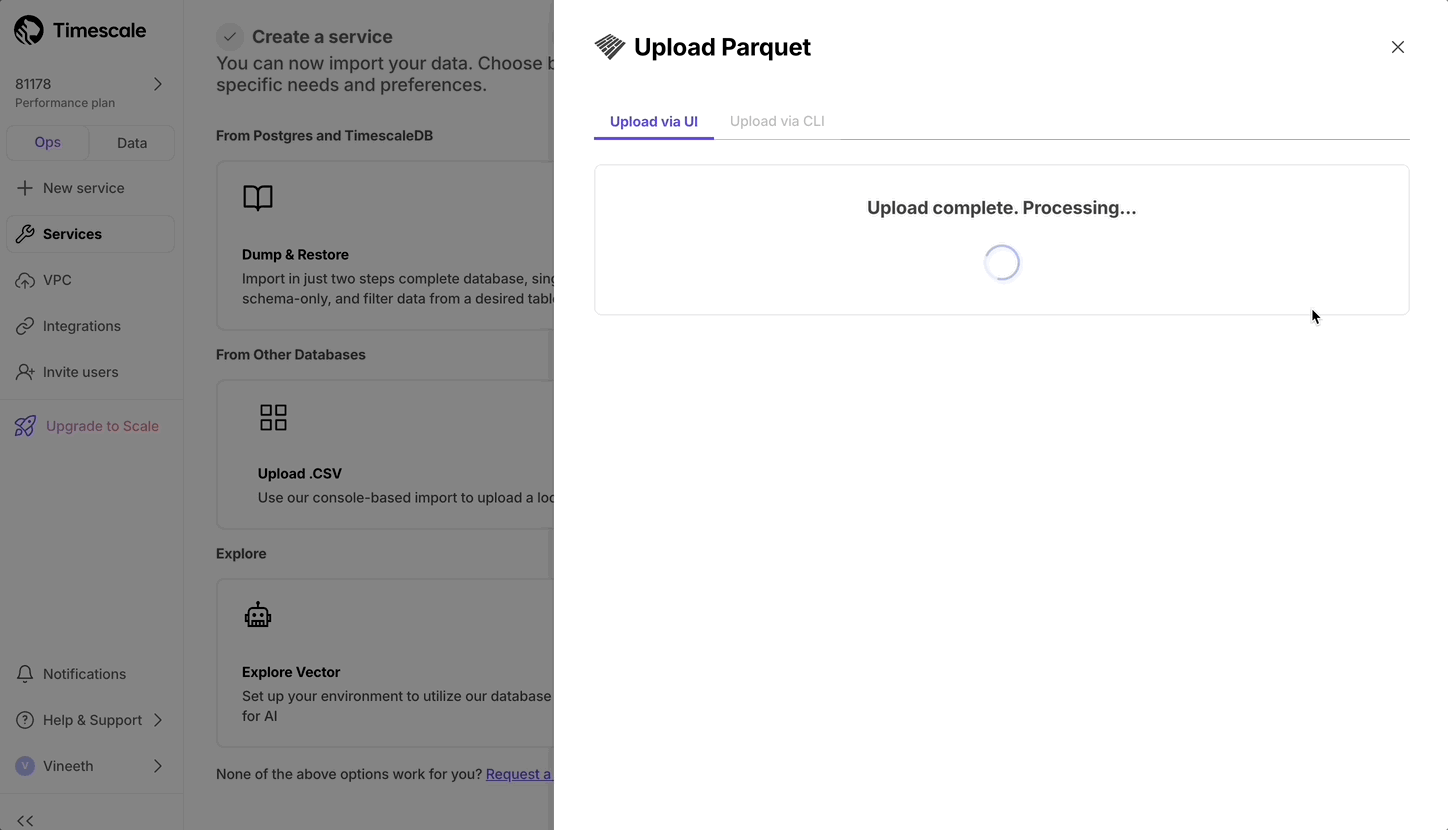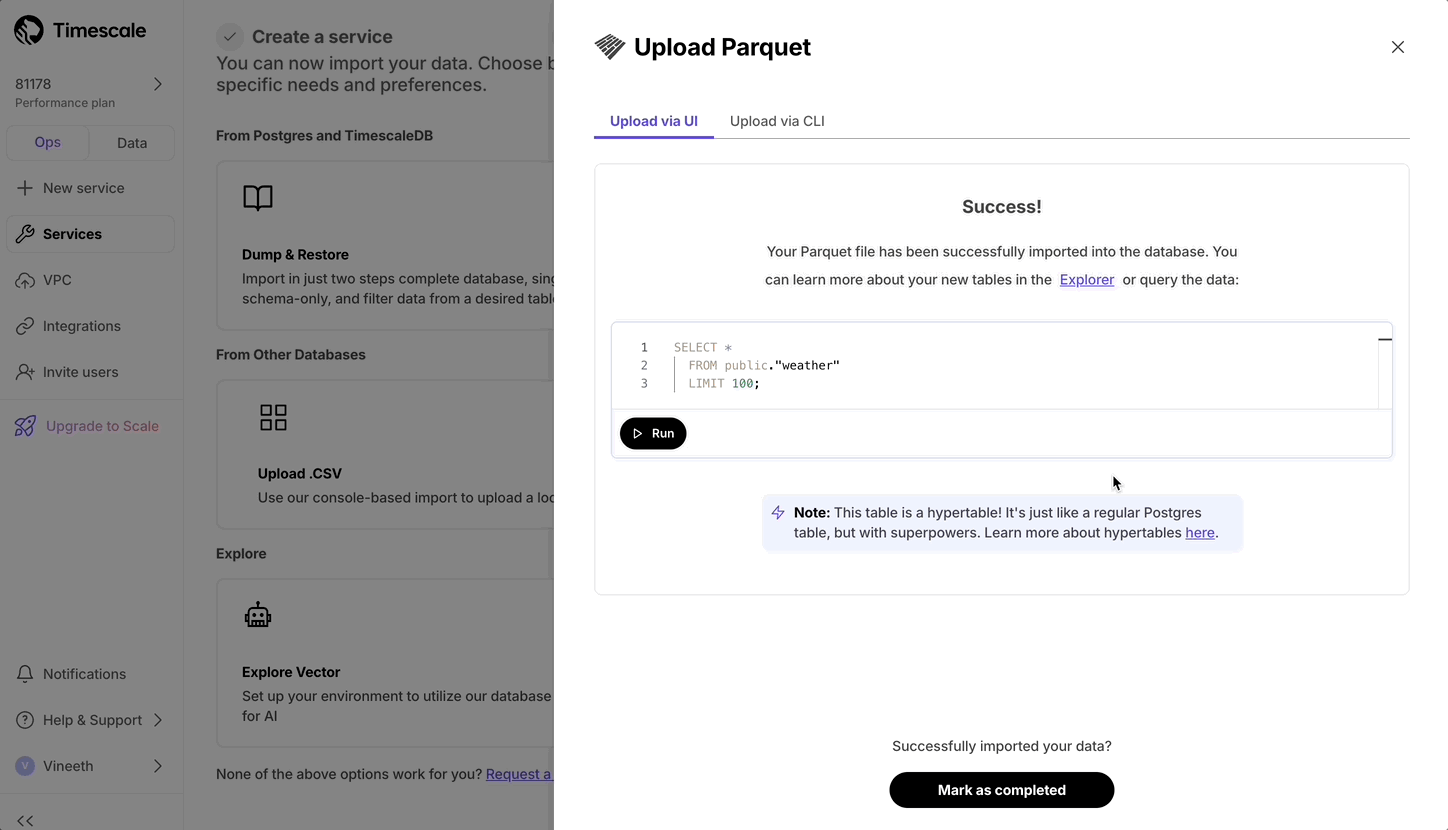
- 在操作模式 SQL 编辑器中,您现在可以突出显示语句以运行特定语句。
Scale 和 Enterprise 客户现在可以直接通过 Timescale Console 配置两个新的多高可用性 (HA) 副本选项
- 两个 HA 副本(均为异步)- 我们的最高可用性配置。
- 两个 HA 副本(一个异步,一个同步)- 我们的最高数据完整性配置。
以前,Timescale 仅为寻求高可用性的客户提供单个同步副本。单个 HA 选项仍然可用。


有关多个 HA 副本的更多详细信息,请参阅 管理高可用性。
在控制台 SQL 编辑器中,我们现在指示您的数据库会话是否健康或已断开连接。如果已断开连接,会话将在您下次执行查询时重新连接。

发布了 live-migration v0.0.26,然后发布了 v0.0.27,其中包括多项性能改进和错误修复,以及对 PostgreSQL 12 的更好支持。
现在,您只需单击即可在控制台的各个位置运行 SQL 语句。这需要为服务启用SQL 编辑器。
通过单击 SQL 语句下方的 运行,从 CAGGs 向导启用连续聚合。

通过单击 SQL 语句下方的 运行,启用数据库扩展。

在成功上传 CSV 文件后,在控制台中单击一下即可立即查询数据。

上周我们宣布了新的控制台内 SQL 编辑器。但是,存在一个限制,即每次执行查询都会创建一个新的数据库会话。
今天我们取消了该限制,并添加了对为每个登录用户保留一个数据库会话的支持,这意味着您可以执行诸如启动事务之类的操作
begin;insert into users (name, email) values ('john doe', 'john@example.com');abort; -- nothing inserted
或使用临时表
create temporary table temp_users (email text);insert into temp_sales (email) values ('john@example.com');-- table will automatically disappear after your session ends
或使用 set 命令
set search_path to 'myschema', 'public';
我们在服务屏幕上添加了一个新选项卡,允许用户直接查询其数据库,而无需离开控制台界面。
- 对于 Timescale 上的现有服务,这是一个选择加入功能。对于所有新创建的服务,SQL 编辑器将默认启用。
- 用户可以随时通过切换“操作”选项卡下的选项来禁用 SQL 编辑器。
- 编辑器支持所有 DML 和 DDL 操作(任何单语句 SQL 查询),但不支持单个查询中的多个 SQL 语句。

服务创建后,我们现在提供了一个专门的数据导入部分,包括从 Postgres 作为源或从 CSV 文件导入的选项。
增强的 Postgres 导入说明现在提供多种选项:单表导入、仅模式导入、部分数据导入(允许选择特定时间范围)和完整数据库导入。 用户只需在数据导入部分提供的 一两个简单命令即可执行任何这些数据导入。

我们发布了 Live migration v0.0.25 版本,其中包含以下改进
- 支持将非公共模式上的 tsdb 迁移到公共模式
- 迁移前兼容性检查
- Docker compose 构建修复
我们在 Timescale Console 中添加了 CSV 导入工具。 对于所有 TimescaleDB 服务,在服务创建后,您可以
- 选择本地文件
- 选择要上传的数据集合的名称(默认为文件名)
- 为每列选择数据类型
- 将文件作为服务中的新超表上传。 在服务创建的
导入数据步骤中查找从 .csv 导入数据磁贴。

客户现在可以更好地了解在 Timescale Cloud 上运行的副本的状态。 我们在服务概览中为读取副本和高可用性副本发布了一个名为“副本延迟”的新参数。 副本延迟以字节为单位进行衡量,相对于主数据库的当前状态。 如果您对副本的相对延迟状态有疑问或疑虑,请联系客户支持。

客户现在可以通过 Timescale UI 调整其超表和连续聚合的块间隔。 在资源管理器中,选择您要调整块间隔的相应超表。 在块信息下,您可以更改块间隔。 请注意,这仅更改将来的块间隔,而不会追溯更改现有块。

我们已发布通过角色承担向 CloudWatch 授予权限的功能。 角色承担对于不再需要轮换凭据和更新其导出器配置的客户来说,既更安全又更方便。
有关更多详细信息,请查看 我们的文档。

我们在“成员”页面中添加了 2FA 状态列,使客户可以轻松查看每个项目成员是否启用了 2FA。

pgai 扩展 v0.3.0 现在支持使用来自 Anthropic 和 Cohere 的模型进行嵌入创建和 LLM 推理。 有关详细信息和示例,请参阅 这篇关于 pgai 和 Cohere 的文章,以及 这篇关于 pgai 和 Anthropic 的文章。
pgvectorscale 扩展 v0.3.0 增加了对 ARM 处理器的支持,并提高了在使用 StreamingDiskANN 索引和低维向量时的召回率。 如果您是自托管,我们建议更新到此版本。
2024 年 8 月 15 日TimescaleDB v2.16.0 在处理压缩数据、连续聚合中扩展的连接支持以及从常规表向超表定义外键的能力方面包含显着的性能改进。 我们建议在下一个可用机会升级。
从今天开始在 Timescale Cloud 上创建的任何新服务都使用 TimescaleDB v2.16.0。
在 TimescaleDB v2.16.0 中,我们
为压缩块上的数据操作操作 (DML) 引入了多项以性能为中心的优化。
在某些情况下,将 upsert 性能提高了 100 倍以上,在某些更新/删除场景中,提高了 500 倍以上。
增加了在压缩超表的非分区列上定义块跳过索引的能力。
当查询在相关列上进行筛选时,TimescaleDB v2.16.0 扩展了块排除以使用这些跳过(稀疏)索引,并修剪不包含用于计算查询响应的任何相关数据的块。
为需要定义外键的用例提供了新选项。
您现在可以从常规表向超表添加外键。 我们还消除了反向方向上一些非常烦人的锁,这些锁在压缩运行时阻止了对引用表的访问。
扩展了连续聚合以支持更多类型的分析查询。
支持更多类型的连接、连接子句上的其他相等运算符以及对多个常规表之间连接的支持。
此版本中的突出功能
通过压缩超表上的块排除提高了查询性能。
您现在可以为具有以下整数数据类型之一的任何列在压缩块上定义块跳过索引:
smallint、int、bigint、serial、bigserial、date、timestamp、timestamptz。在列上调用
enable_chunk_skipping后,TimescaleDB 会跟踪该列的最小值和最大值,并使用此信息排除在该列上筛选的查询的块,其中找不到任何数据。提高了压缩超表上的 upsert 性能。
通过使用索引扫描来验证压缩块上的插入期间的约束,TimescaleDB 将某些 ON CONFLICT 子句的速度提高了 100 倍以上。
提高了压缩超表上更新、删除和插入的性能。
通过在访问压缩数据时和解压缩之前过滤数据,TimescaleDB 提高了所有类型的压缩块上的更新和删除以及具有唯一约束的压缩块上的插入的性能。
通过在不解压缩的情况下发出约束冲突信号,或者仅在更新、删除和 upsert 的情况下找到匹配记录时才解压缩,TimescaleDB v2.16.0 在某些更新/删除场景中将这些操作的速度提高了 1000 倍以上,对于 upsert 提高了 10 倍。
您可以从常规表向超表添加外键,并支持所有类型的级联选项。 这对于使用顺序 ID 分区的超表以及需要从其他表引用这些 ID 的情况非常有用。
在压缩具有外键的超表期间降低锁定要求
高级外键处理消除了在压缩新块时锁定引用表的需要。 当在超表上运行压缩时,DML 不再阻止对引用表的访问。
改进了对连续聚合查询的支持
现在支持
INNER/LEFT和LATERAL连接。 此外,您现在可以与多个常规表连接,并且在连接子句中可以使用多个相等运算符。
PostgreSQL 13 支持移除公告
继 TimescaleDB v2.13 中发布的 PostgreSQL 13 弃用公告之后,TimescaleDB v2.16 不再支持 PostgreSQL 13。
当前支持的 PostgreSQL 主要版本为 14、15 和 16。
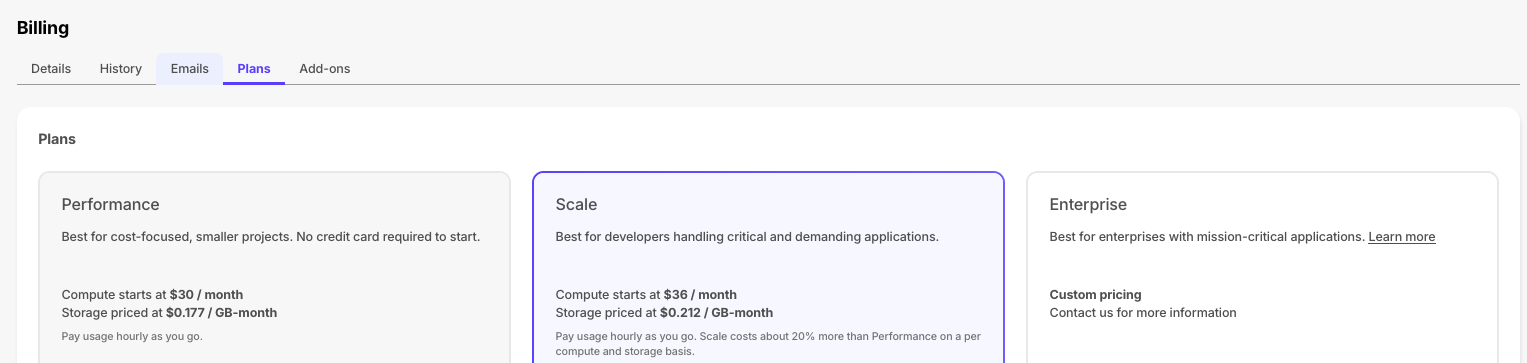
2024 年 8 月 8 日为了支持不断变化的客户需求,Timescale Cloud 现在提供三个计划,以提供更高的价值、灵活性和效率。
- 性能版: 适用于注重成本的小型项目。 无需信用卡即可开始。
- 规模版: 适用于处理关键和高要求的应用程序的开发人员。
- 企业版: 适用于具有任务关键型应用程序的企业。
每个计划都继续根据每小时使用量计费,主要针对您运行的计算和您消耗的存储。 您可以随时通过 Console UI 在性能版和规模版计划之间升级或降级。 有关这些定价计划的具体细节和差异的更多信息,请参见 此处文档。
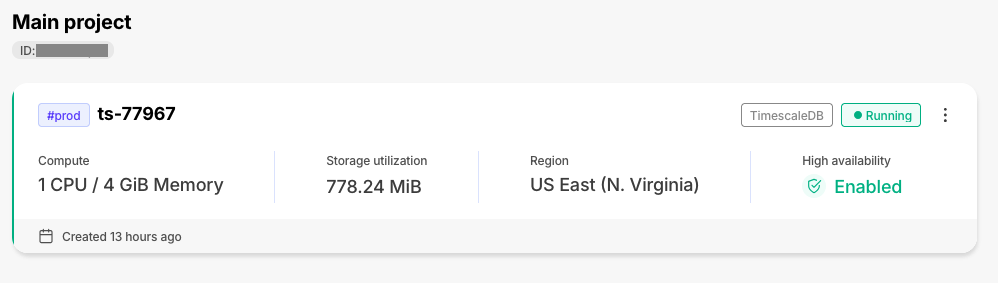
服务页面上的各个磁贴已通过新信息得到增强,包括高可用性状态。 这将使您可以更好地一目了然地评估您的服务状态。
改进
- 现在可以为迁移的初始数据复制提供自动重试
- 现在也使用 pgcopydb 进行从 PG 到 TSDB 迁移的初始数据复制(TS 到 TS 迁移已使用),这具有显着的性能提升。
- 修复了 TimescaleDB v2.13.x 迁移的问题
- 支持具有自定义模式和表前缀的超表的块映射
以下改进已应用于 Timescale 产品
Timescale Cloud:
- 连接池已更新,现在避免多次重新加载
- tsdbadmin 用户现在可以将以下角色授予其他用户:
pg_checkpoint、pg_monitor、pg_signal_backend、pg_read_all_stats、pg_stat_scan_tables - Timescale Console 更加可靠。
TimescaleDB
以下改进已应用于 Timescale live-migration docker 镜像
- 现在在实时迁移期间可以使用基于表的筛选。
- pbcopydb 的改进提高了性能并消除了无用的警告消息。
- 用户通知日志使您始终可以选择迁移运行的最新版本。
为了提高稳定性和新功能,请更新到最新的 timescale/live-migration docker 镜像。 要了解更多信息,请参阅 实时迁移文档。
2024 年 6 月 21 日Ollama 现在已与 pgai 集成。
Ollama 是启动和运行开源语言模型的最简单和最流行的方式。 将 Ollama 视为 LLM 的 Docker,可以轻松访问和使用各种开源模型,如 Llama 3、Mistral、Phi 3、Gemma 等。
通过将 pgai 扩展集成到您的数据库中,使用 SQL 将 Ollama AI 嵌入到您的应用程序中。 例如
select ollama_generate( 'llava:7b', 'Please describe this image.', _images=> array[pg_read_binary_file('/pgai/tests/postgresql-vs-pinecone.jpg')], _system=>'you are a helpful assistant', _options=> jsonb_build_object( 'seed', 42, 'temperature', 0.9))->>'response';
要了解更多信息,请参阅 pgai Ollama 文档。
2024 年 6 月 13 日压缩向导现已在 Timescale Cloud 上可用。 选择一个超表,并通过 UI 指导您完成启用压缩的过程!
要访问压缩向导,请导航到 资源管理器,然后选择您要压缩的超表。 在右上角,将鼠标悬停在 压缩已关闭 的位置,然后打开向导。 然后,您将获得有关为超表配置压缩的过程指导,并且可以直接通过 UI 压缩它。

vectorscale 扩展 现已在 Timescale Cloud 上可用。
pgvectorscale 补充了 pgvector(PostgreSQL 的开源向量数据扩展),并为 pgvector 数据引入了以下关键创新
- 一种名为 StreamingDiskANN 的新索引类型,灵感来自 DiskANN 算法,基于 Microsoft 的研究。
- 统计二进制量化:由 Timescale 研究人员开发,这种压缩方法改进了标准二进制量化。
在 5000 万个 Cohere 嵌入(每个 768 维)的基准数据集上,PostgreSQL 与 pgvector 和 pgvectorscale 相比 Pinecone 的存储优化 (s1) 索引,在 99% 召回率的近似最近邻查询中实现了 28 倍更低的 p95 延迟和 16 倍更高的查询吞吐量,所有这些都在 AWS EC2 上自托管时成本降低 75%。
要了解更多信息,请参阅 pgvectorscale 文档。
2024 年 6 月 11 日pgai 扩展 现已在 Timescale Cloud 上可用。
pgai 将嵌入和生成 AI 模型更靠近数据库。 使用 pgai,您现在可以直接从 PostgreSQL 中的 SQL 查询中执行以下操作
- 为您的数据创建嵌入。
- 从 OpenAI GPT4o 等模型检索 LLM 聊天完成。
- 对您的数据进行推理,并促进分类、摘要和数据丰富等用例,这些用例在 PostgreSQL 中针对您现有的关系数据。
要了解更多信息,请参阅 pgai 文档。
2024 年 6 月 7 日2.15.x 版本包含性能改进和错误修复。 这些版本中的亮点是
- 连续聚合现在支持带有 origin 和/或 offset 的
time_bucket。 - 超表压缩具有以下改进
- 在通过分析表配置和统计信息配置压缩时,建议为 segment by 和 order by 使用优化的默认值。
- 添加了计划器支持,以在解压缩之前检查更多种类的 WHERE 条件。 这减少了必须解压缩的行数。
- 现在,当您压缩具有 btree 索引的列时,可以使用 minmax 稀疏索引。
- 向量化 WHERE 子句中包含文本相等运算符和 LIKE 表达式的过滤器。
要了解更多信息,请参阅 TimescaleDB 发行说明。
2024 年 5 月 31 日PostgreSQL 审计扩展 (pgaudit) 现已在 Timescale Cloud 上可用。 pgaudit 在 Timescale Cloud 日志中提供详细的数据库会话和对象审计日志记录。
如果您有严格的安全性和合规性要求,并且需要记录数据库级别的所有操作,pgaudit 可以提供帮助。 您还可以将这些审计日志导出到 Amazon CloudWatch。
要了解更多信息,请参阅 pgaudit 文档。
2024 年 5 月 31 日PostgreSQL 扩展 (unit) 的 SI 单位 为 ISU 在 Timescale Cloud 中提供支持。
您可以使用 Timescale Cloud 来解决日常问题。 例如,要查看 50°C 等于多少 °F,请在您的 Timescale Cloud 服务中运行以下查询
SELECT '50°C'::unit @ '°F' as temp;temp--------122 °F(1 row)
要了解更多信息,请参阅 postgresql-unit 文档。
关键词