本文档提供了详细的分步说明,指导您使用双写和回填迁移方法,将数据从使用 PostgreSQL 的源数据库迁移到 Timescale。

注意
在迁移的上下文中,您现有的生产数据库被称为“源”数据库,而您打算将数据迁移到的新 Timescale 数据库被称为“目标”数据库。
详细而言,迁移过程包括以下步骤
- 在 Timescale 中设置目标数据库实例。
- 修改应用程序以写入目标数据库。
- 将模式和关系数据从源迁移到目标。
- 以双写模式启动应用程序。
- 确定完成点
T。 - 将时序数据从源回填到目标。
- 验证所有数据是否都存在于目标数据库中。
- 验证目标数据库是否可以处理生产负载。
- 切换应用程序以将目标数据库视为主要数据库(可能继续写入源数据库,作为备份)。

提示
如果您遇到困难,可以通过提交支持请求获得帮助,或者将您的问题发送到社区 Slack中的 #migration 频道,该迁移方法的开发人员将在那里提供帮助。
您可以直接从Timescale 控制台提交支持请求,或发送电子邮件至 support@timescale.com。
如果您打算迁移超过 400 GB 的数据,请提交支持请求以确保在您的 Timescale 实例上预先配置足够的磁盘空间。
您可以直接从Timescale 控制台提交支持请求,或发送电子邮件至 support@timescale.com。
具体如何操作取决于您的应用程序使用的语言,以及您的摄取和应用程序功能的具体方式。在最简单的情况下,您只需并行执行两个插入操作。在一般情况下,您必须考虑如何处理写入源数据库或目标数据库失败的情况,以及您想要或可以构建什么机制来从这种失败中恢复。
如果您的时序数据具有对普通表的外键引用,您必须确保您的应用程序正确维护外键关系。如果被引用的列是 *SERIAL 类型,则插入到源数据库和目标数据库的同一行可能不会获得相同的自动生成的 ID。如果发生这种情况,从源回填到目标的数据在内部是不一致的。在最好的情况下,它会导致外键违规,在最坏的情况下,外键约束得到维护,但数据引用了错误的外键。为了避免这些问题,最佳实践是遵循在线迁移。
您可能还希望在源数据库和目标数据库上执行相同的读取查询,以评估查询结果的正确性和性能。请记住,目标数据库在一段时间内没有所有数据,因此您应该预期在一段时间内(可能几天)结果不会相同。
您可能希望将一些包含时序数据的大型表转换为超表。此步骤包括识别这些表,从数据库转储中排除它们的数据,复制数据库模式和表,并将时序表设置为超表。数据将在后续步骤中回填到这些超表中。
注意
为了方便起见,在本指南中,源数据库和目标数据库的连接字符串分别称为 $SOURCE 和 $TARGET。这可以在您的 shell 中设置,例如
export SOURCE="postgres://<user>:<password>@<source host>:<source port>/<db_name>"export TARGET="postgres://<user>:<password>@<target host>:<target port>/<db_name>"
pg_dumpall -d "$SOURCE" \-l $DB_NAME \--quote-all-identifiers \--roles-only \--file=roles.sql
Timescale 服务不支持具有超级用户访问权限的角色。如果您的 SQL 转储包含具有此类权限的角色,您需要修改该文件以符合安全模型。
您可以使用以下 sed 命令从您的 roles.sql 文件中删除不支持的语句和权限
sed -i -E \-e '/CREATE ROLE "postgres";/d' \-e '/ALTER ROLE "postgres"/d' \-e '/CREATE ROLE "tsdbadmin";/d' \-e '/ALTER ROLE "tsdbadmin"/d' \-e 's/(NO)*SUPERUSER//g' \-e 's/(NO)*REPLICATION//g' \-e 's/(NO)*BYPASSRLS//g' \-e 's/GRANTED BY "[^"]*"//g' \roles.sql
注意
此命令仅适用于 GNU 版本的 sed(有时称为 gsed)。对于 BSD 版本(macOS 上的默认版本),您需要添加一个额外的参数来将 -i 标志更改为 -i ''。
要检查 sed 版本,您可以使用命令 sed --version。虽然 GNU 版本明确地将自己标识为 GNU,但 BSD 版本的 sed 通常不提供直接的 --version 标志,而只是输出“非法选项”错误。
此脚本的简要说明是
CREATE ROLE "postgres"; 和ALTER ROLE "postgres":这些语句被删除是因为它们需要超级用户访问权限,而 Timescale 不支持。(NO)SUPERUSER|(NO)REPLICATION|(NO)BYPASSRLS:这些是需要超级用户访问权限的权限。GRANTED BY role_specification:GRANTED BY 子句也可能具有需要超级用户访问权限的权限,因此应将其删除。注意:根据 TimescaleDB 文档,GRANTED BY 子句中的 GRANTOR 必须是当前用户,并且此子句主要用于 SQL 兼容性。因此,可以安全地删除它。
超表的理想候选对象是包含时序数据的大型表。这通常是具有某种形式的时间戳值(TIMESTAMPTZ、TIMESTAMP、BIGINT、INT 等)作为主要维度,以及一些其他测量值的数据。
pg_dump -d "$SOURCE" \--format=plain \--quote-all-identifiers \--no-tablespaces \--no-owner \--no-privileges \--exclude-table-data=<table name or pattern> \--file=dump.sql
--exclude-table-data用于排除超表候选对象的所有数据。您可以指定表模式,也可以多次指定--exclude-table-data,每次指定一个要转换的表。
--no-tablespaces是必需的,因为 Timescale 不支持默认表空间以外的表空间。这是一个已知的限制。--no-owner是必需的,因为 Timescale 的tsdbadmin用户不是超级用户,并且在所有情况下都不能分配所有权。此标志意味着一切都由用于连接到目标的用户拥有,而与源中的所有权无关。这是一个已知的限制。--no-privileges是必需的,因为 Timescale 的tsdbadmin用户不是超级用户,并且在所有情况下都不能分配权限。此标志意味着分配给其他用户的权限必须在目标数据库中作为手动清理任务重新分配。这是一个已知的限制。
psql -X -d "$TARGET" \-v ON_ERROR_STOP=1 \--echo-errors \-f roles.sql \-f dump.sql
对于应在目标数据库中转换为超表的每个表,执行
SELECT create_hypertable('<table name>', by_range('<time column name>'));
注意
by_range 维度构建器是 TimescaleDB 2.13 的新增功能。对于更简单的情况,例如这种情况,您也可以使用旧语法创建超表
SELECT create_hypertable('<table name>', '<time column name>');
有关您可以传递给 create_hypertable 的选项的更多信息,请查阅create_table API 参考。有关超表的一般信息,请查阅超表文档。
您可能还希望考虑利用 Timescale 的一些杀手级功能,例如
设置好目标数据库后,您的应用程序现在可以以双写模式启动。
在双写执行一段时间后,目标超表包含三个时间范围内的数据:缺失写入、延迟到达数据和“一致性”范围
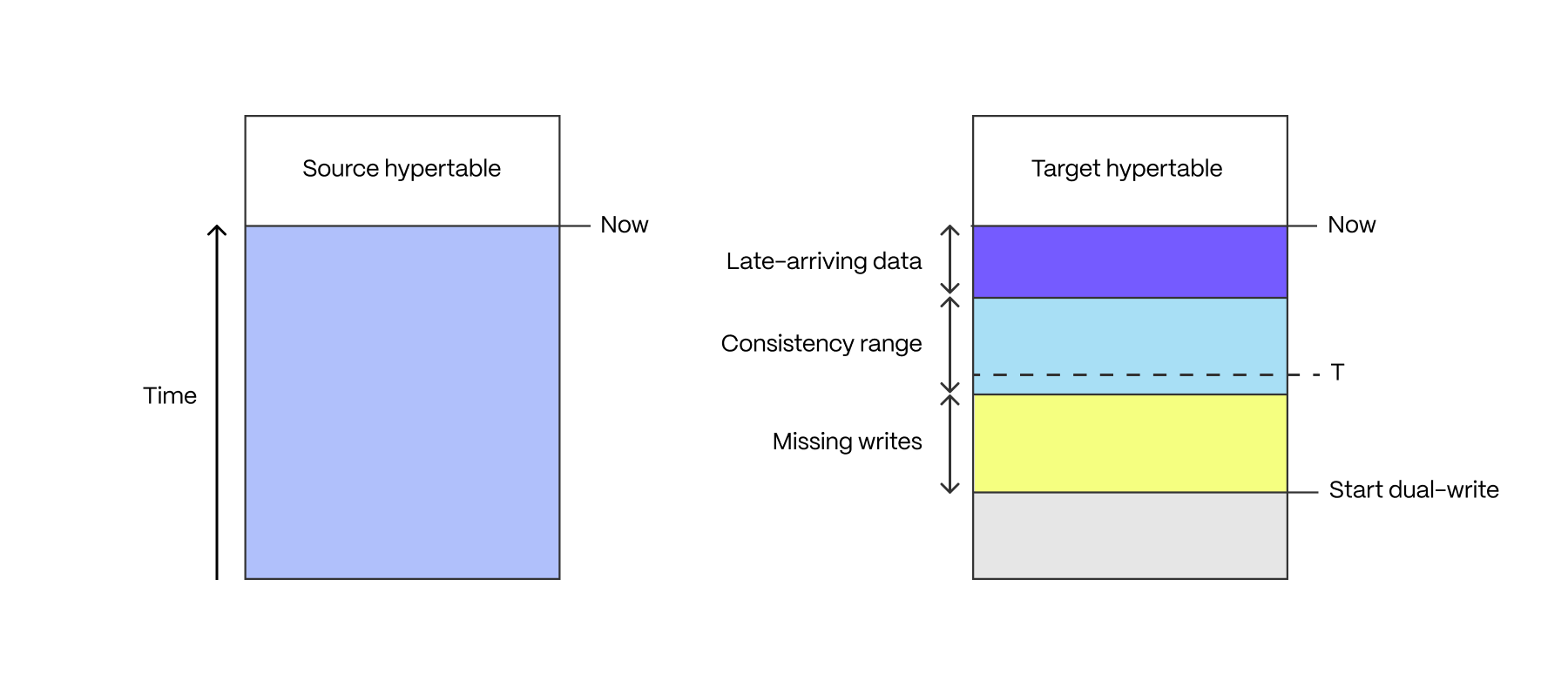
如果应用程序由多个写入器组成,并且这些写入器并非同时开始写入目标超表,则会有一段时间内并非所有写入都已进入目标超表。此期间从第一个写入器开始双写时开始,到最后一个写入器开始双写时结束。
某些应用程序具有延迟到达数据:时间戳在过去但尚未写入的测量值(例如,来自具有间歇性连接问题的设备)。延迟到达数据的窗口介于当前时刻和最大延迟之间。
一致性范围是没有缺失写入且所有数据都已到达的范围,即介于缺失写入范围的结束和延迟到达数据范围的开始之间。
这些范围的长度由应用程序的属性定义,没有一刀切的方法来确定它们是什么。
完成点 T 是在一致性范围内任意选择的时间。它是可以安全回填数据的时间点,确保不会丢失数据。
完成点应表示为要回填的超表的 time 列的类型。例如,如果您使用 TIMESTAMPTZ time 列,则完成点可能是 2023-08-10T12:00:00.00Z。如果您使用 BIGINT 列,则可能是 1695036737000。
如果您为超表的 time 列混合使用类型,则必须分别为每种类型确定完成点,并将每组具有相同类型的超表与其他类型的超表独立回填。
将源数据库中的数据按表转储为 CSV 格式,并使用 timescaledb-parallel-copy 工具将这些 CSV 恢复到目标数据库中。
确定要从源数据库复制到目标数据库的数据窗口。根据源表中的数据量,将源表拆分为多个数据块以独立移动可能是明智之举。在以下步骤中,此时间范围称为 <start> 和 <end>。
通常,time 列的类型为 timestamp with time zone,因此 <start> 和 <end> 的值必须类似于 2023-08-01T00:00:00Z。如果 time 列不是 timestamp with time zone,则 <start> 和 <end> 的值必须是该列的正确类型。
如果您打算复制源表中的所有历史数据,则 <start> 的值可以是 '-infinity',而 <end> 值是您确定的完成点 T 的值。
双写过程可能已在您要移动的时间范围内将数据写入目标数据库。在这种情况下,必须删除双写的数据。这可以使用 DELETE 语句来实现,如下所示
psql $TARGET -c "DELETE FROM <hypertable> WHERE time >= <start> AND time < <end>);"

重要提示
BETWEEN 运算符包含开始和结束范围,因此不建议使用它。
在回填数据时,必须关闭目标超表的压缩策略。这可以防止压缩策略压缩仅半满的块。
在以下命令中,将 <hypertable> 替换为目标超表的完全限定表名,例如 public.metrics
psql -d $TARGET -f -v hypertable=<hypertable> - <<'EOF'SELECT public.alter_job(j.id, scheduled=>false)FROM _timescaledb_config.bgw_job jJOIN _timescaledb_catalog.hypertable h ON h.id = j.hypertable_idWHERE j.proc_schema IN ('_timescaledb_internal', '_timescaledb_functions')AND j.proc_name = 'policy_compression'AND j.id >= 1000AND format('%I.%I', h.schema_name, h.table_name)::text::regclass = :'hypertable'::text::regclass;EOF
执行以下命令,将 <source table> 和 <hypertable> 分别替换为源表和目标超表的完全限定名称
psql $SOURCE -f - <<EOF\copy ( \SELECT * FROM <source table> WHERE time >= <start> AND time < <end> \) TO stdout WITH (format CSV);" | timescaledb-parallel-copy \--connection $TARGET \--table <hypertable> \--log-batches \--batch-size=1000 \--workers=4EOF
上述命令不是事务性的。如果存在连接问题或其他导致复制停止的问题,则必须从目标中删除部分复制的行(使用上面步骤 6b 中的说明),然后可以重新启动复制。
在以下命令中,将 <hypertable> 替换为目标超表的完全限定表名,例如 public.metrics
psql -d $TARGET -f -v hypertable=<hypertable> - <<'EOF'SELECT public.alter_job(j.id, scheduled=>true)FROM _timescaledb_config.bgw_job jJOIN _timescaledb_catalog.hypertable h ON h.id = j.hypertable_idWHERE j.proc_schema IN ('_timescaledb_internal', '_timescaledb_functions')AND j.proc_name = 'policy_compression'AND j.id >= 1000AND format('%I.%I', h.schema_name, h.table_name)::text::regclass = :'hypertable'::text::regclass;EOF
现在所有数据都已回填,并且应用程序正在向两个数据库写入数据,两个数据库的内容应该相同。如何最好地验证这一点取决于您的应用程序。
如果您为每个生产查询并行从两个数据库读取数据,您可以考虑添加应用程序级别的验证,以验证两个数据库是否返回相同的数据。
另一种选择是比较源表和目标表中的行数,尽管这会读取表中的所有数据,这可能会对您的生产工作负载产生影响。
另一种选择是在源表和目标表上运行 ANALYZE,然后查看 pg_class 表的 reltuples 列。这不完全精确,但不需要从表中读取所有行。注意:对于超表,reltuples 值属于块表,因此您必须对属于超表的所有块的 reltuples 求和。如果块在一个数据库中被压缩,而在另一个数据库中未被压缩,则无法使用此检查。
现在双写已经到位一段时间了,目标数据库应该可以承受生产写入流量。现在是确定目标数据库是否可以服务所有生产流量(包括读取和写入)的合适时机。具体如何完成取决于应用程序,由您自行决定。
一旦您验证了所有数据都存在,并且目标数据库可以处理生产工作负载,最后一步是将目标数据库切换为您的主要数据库。您可能希望继续写入源数据库一段时间,直到您确定目标数据库可以承受所有生产流量。
关键词
在此页面上发现问题?报告问题 或 在 GitHub 上编辑此页。