
警告
TimescaleDB v2.13 是最后一个为 PostgreSQL 版本 13、14 和 15 提供多节点支持的版本。
分布式超表是跨越多个节点的超表。使用分布式超表,您可以跨多台机器扩展数据存储。数据库还可以并行化某些插入和查询。
分布式超表仍然表现得像一个单表。您可以像使用标准超表一样使用它。要了解有关超表的更多信息,请参阅超表部分。
某些细微差别可能会影响分布式超表的性能。本节解释分布式超表的工作原理,以及在采用分布式超表之前需要考虑的事项。
分布式超表与多节点集群一起使用。每个集群都有一个访问节点和多个数据节点。您使用访问节点连接到数据库,数据存储在数据节点上。有关多节点的更多信息,请参阅多节点部分。
您在访问节点上创建分布式超表。它的数据块存储在数据节点上。当您插入数据或运行查询时,访问节点与相关的数据节点通信,并在可能的情况下下推任何处理。
分布式超表始终按时间分区,就像标准超表一样。但与标准超表不同,分布式超表也应按空间分区。这允许您在数据节点之间平衡插入和查询,类似于传统的分片。如果没有空间分区,同一时间范围内的所有数据都将写入单个节点上的同一数据块。
默认情况下,Timescale 创建的空间分区数与数据节点数相同。您可以更改此数字,但过多的空间分区会降低性能。它会增加某些查询的计划时间,并导致在将项目映射到分区时平衡性较差。
数据通过哈希分配给空间分区。空间维度中的每个哈希桶都对应一个数据节点。一个数据节点可以容纳多个桶,但对于每个时间间隔,每个桶可能只属于一个节点。
当空间分区开启时,使用 2 个维度将数据划分为数据块:时间维度和空间维度。您可以指定沿空间维度的分区数。数据通过哈希其在该维度上的值分配给分区。
例如,假设您使用 device_id 作为空间分区列。对于每一行,device_id 列的值都会被哈希。然后,该行被插入到该哈希值的正确分区中。

空间分区维度可以是开放的或封闭的。封闭维度具有固定数量的分区,通常使用一些哈希来将值匹配到分区。开放维度没有固定数量的分区,通常每个数据块覆盖一定的范围。在大多数情况下,时间维度是开放的,而空间维度是封闭的。
如果您使用 create_hypertable 命令创建超表,则空间维度是开放的,并且无法调整。要创建具有封闭空间维度的超表,请首先仅使用时间维度创建超表。然后使用 add_dimension 命令显式添加开放设备。如果将范围设置为 1,则每个设备都有自己的数据块。这可以帮助您解决常规空间维度的一些限制,并且如果您希望使某些数据块易于排除,则特别有用。
您可以通过添加额外的数据节点来扩展分布式超表。如果您现在的空间分区数少于数据节点数,则需要增加空间分区数以利用新节点。新的分区配置仅影响新的数据块。在此图中,在第三个时间间隔期间添加了一个额外的数据节点。第四个时间间隔现在包含四个数据块,而之前的时间间隔仍然包含三个
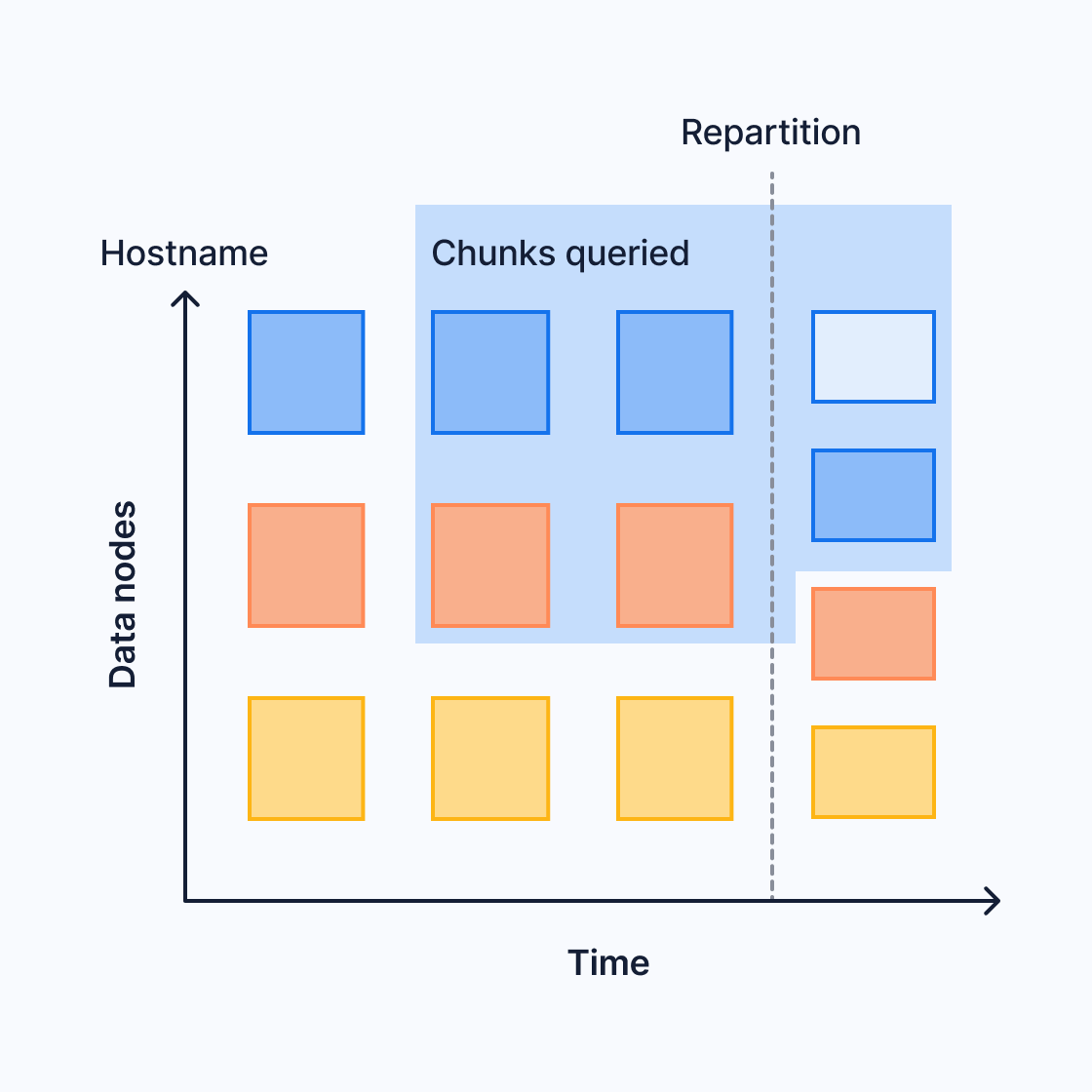
这可能会影响跨越两种不同分区配置的查询。有关更多信息,请参阅关于查询下推的限制部分。
要在数据块级别复制分布式超表,请配置超表以将每个数据块写入多个数据节点。这种原生复制确保分布式超表免受数据节点故障的影响,并提供了另一种选择,即使用流复制完全复制每个数据节点以提供高可用性。只有数据节点使用此方法复制。访问节点不被复制。
有关复制和高可用性的更多信息,请参阅多节点 HA 部分。
分布式超表水平扩展您的数据存储,因此您不受任何单台机器的存储限制。它还提高了某些查询的性能。
您的性能是否以及提高多少取决于您的查询模式和数据分区。当访问节点可以将查询处理下推到数据节点时,性能会提高。例如,如果您使用 GROUP BY 子句进行查询,并且数据按 GROUP BY 列分区,则数据节点可以执行处理,并且仅将最终结果发送到访问节点。
如果无法在数据节点上完成处理,则访问节点需要拉取原始数据或部分处理的数据,并在本地进行处理。有关更多信息,请参阅查询下推的限制。
访问节点可以使用完全或部分方法来下推查询。可以下推的计算包括排序和分组。目前不支持数据节点上的连接。
要查看查询如何下推到数据节点,请使用 EXPLAIN VERBOSE 来检查查询计划和发送到每个数据节点的远程 SQL 语句。
在完全下推方法中,访问节点将所有计算卸载到数据节点。它从数据节点接收最终结果并附加它们。要完全下推聚合查询,GROUP BY 子句必须包含以下任一项
- 所有分区列或
- 仅第一个空间分区列
例如,假设您要计算每个位置的 max 温度
SELECT location, max(temperature)FROM conditionsGROUP BY location;
如果 location 是您唯一的空间分区,则每个数据节点都可以在其自己的数据子集上计算最大值。
在部分下推方法中,访问节点将大部分计算卸载到数据节点。它从数据节点接收部分结果,并通过组合这些部分结果来计算最终聚合。
例如,假设您要计算所有位置的 max 温度。每个数据节点计算一个局部最大值,访问节点通过计算所有局部最大值的最大值来计算最终结果
SELECT max(temperature) FROM conditions;
当分布式超表可以将查询下推到数据节点时,它们会获得更高的性能。但查询计划器可能无法下推每个查询。或者它可能只能部分下推查询。这可能是由于以下几个原因
- 您更改了分区配置。例如,您添加了新的数据节点并增加了空间分区数以匹配。这可能会导致同一空间值的数据块存储在不同的节点上。例如,假设您按
device_id分区。您从 3 个分区开始,device_B的数据存储在节点 3 上。稍后您增加到 4 个分区。device_B的新数据块现在存储在节点 4 上。如果您跨越重新分区边界进行查询,则无法仅在节点 3 或节点 4 上计算device_B的最终聚合。部分处理的数据必须发送到访问节点以进行最终聚合。Timescale 查询计划器动态检测此类重叠数据块并恢复到适当的部分聚合计划。这意味着您可以添加数据节点并重新分区数据以实现弹性,而无需担心查询结果。在某些情况下,您的查询性能可能会略有下降,但这很少见,并且受影响的数据块通常会快速移出您的保留窗口。 - 查询包含非不可变函数和表达式。该函数无法下推到数据节点,因为根据定义,不能保证每个节点的结果一致。非不可变函数的一个示例是
random(),它取决于当前种子。 - 查询包含用户定义的函数。访问节点假定该函数在数据节点上不存在,因此不会将其下推。
Timescale 使用多种优化来避免这些限制,并尽可能下推更多查询。例如,now() 是一个非不可变函数。数据库在访问节点上将其转换为常量,并将常量时间戳下推到数据节点。
您可以在与标准超表和标准 PostgreSQL 表相同的数据库中使用分布式超表。这在很大程度上与拥有多个标准表的工作方式相同,但有一些差异。例如,如果您 JOIN 标准表和分布式超表,则访问节点需要从数据节点获取原始数据并在本地执行 JOIN。
关键词
在此页面上发现问题?报告问题 或 在 GitHub 中编辑此页面。