
警告
TimescaleDB v2.13 是最后一个为 PostgreSQL 版本 13、14 和 15 提供多节点支持的版本。
如果您有更大的 PB 级工作负载,您可能需要多个 TimescaleDB 实例。TimescaleDB 多节点允许您运行和管理数据库集群,这可以为您提供更快的数据摄取,以及对大型工作负载更快速和高效的查询。

重要提示
在某些情况下,由于各个节点之间额外的网络通信,您的查询在多节点集群中可能会变慢。当查询处理分布在节点之间,并且结果集相对于查询数据集较小时,查询性能最佳。重要的是,在开始之前了解多节点架构,并根据您的具体要求规划数据库。
多节点 TimescaleDB 允许您将多个数据库绑定到一起,形成一个逻辑分布式数据库,以结合多个物理 PostgreSQL 实例的处理能力。
其中一个数据库存在于访问节点上,并存储关于其他数据库的元数据。其他数据库位于数据节点上,并保存实际数据。理论上,PostgreSQL 实例可以在不同的数据库中同时充当访问节点和数据节点。但是,建议不要使用混合设置,因为它可能很复杂,并且服务器实例通常根据它们所扮演的角色进行不同的配置。
对于自托管安装,创建一个可以充当访问节点的服务器,然后使用该访问节点在其他服务器上创建数据节点。
当您配置了多节点 TimescaleDB 后,访问节点会协调数据块在数据节点上的放置和访问。在大多数情况下,建议您使用多维分区来跨时间和空间维度在数据块中分布数据。本节中的图示显示了访问节点 (AN) 如何在同一时间间隔内跨多个数据节点(DN1、DN2 和 DN3)分区数据。
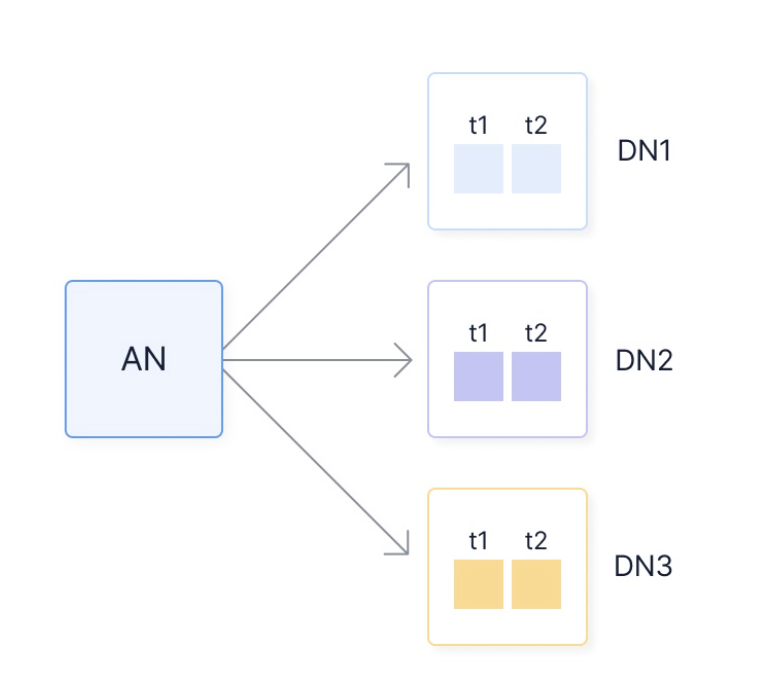
数据库用户连接到访问节点以发出命令和执行查询,类似于连接到常规单节点 TimescaleDB 实例的方式。在大多数情况下,无需直接连接到数据节点。
由于 TimescaleDB 作为特定数据库中的扩展存在,因此可以在同一访问节点上同时拥有分布式和非分布式数据库。也可以有多个分布式数据库,它们使用不同的物理实例集作为数据节点。但是,在本节中,假设您有一个包含一致数据节点集的单个分布式数据库。
如果您在分布式数据库上使用常规表或超表,它们不会自动分布。即使底层数据库是分布式的,常规表和超表仍然像往常一样工作。要启用多节点功能,您需要在访问节点上显式创建一个分布式超表,以利用数据节点。分布式超表类似于常规的 超表,但不同之处在于数据块分布在数据节点上,而不是本地存储上。通过分布数据块,数据节点的处理能力被结合起来,以实现更高的摄取吞吐量和更快的查询。但是,实现良好性能的能力高度依赖于数据在数据节点上的分区方式。
为了实现良好的摄取性能,请批量写入数据,每个批次包含可以分布在多个数据节点上的数据。为了实现良好的查询性能,请将查询分散到多个节点,并使结果集相对于处理的数据量较小。为了实现这一点,考虑合适的分区方法非常重要。
摄取到分布式超表中的数据根据您选择的分区方法分布在数据节点上。可以从访问节点发送到多个数据节点并同时处理的查询通常比在单个数据节点上运行的查询运行得更快,因此重要的是考虑您拥有哪种类型的数据,以及您想要运行的查询类型。
TimescaleDB 多节点当前支持使其最适合大规模时间序列工作负载的功能,这些工作负载在 time 和空间维度(例如 location)上进行分区。如果您通常运行跨多个位置和设备聚合数据的宽查询,请选择此分区方法。例如,像这样的查询在按 time,location 分区的数据库上更快,因为它将工作并行地分散在所有数据节点上
SELECT time_bucket('1 hour', time) AS hour, location, avg(temperature)FROM conditionsGROUP BY hour, locationORDER BY hour, locationLIMIT 100;
如果您还需要更快的插入性能,则按 time 和空间维度(例如 location)进行分区也是最佳选择。如果您仅按时间分区,并且您的插入通常按时间顺序发生,那么您始终一次写入一个数据节点。按 time 和 location 分区意味着您的按时间顺序的插入将分散在多个数据节点上,这可以带来更好的性能。
如果您主要对单个位置运行深度时间查询,您可能会发现仅按 time 维度或除 location 之外的空间维度进行分区可以获得更好的性能。例如,像这样的查询在仅按 time 分区的数据库上更快,因为单个位置的数据分散在所有数据节点上,而不是位于单个节点上
SELECT time_bucket('1 hour', time) AS hour, avg(temperature)FROM conditionsWHERE location = 'office_1'GROUP BY hourORDER BY hourLIMIT 100;
在分布式超表上发生的事务是原子性的,就像在常规超表上一样。这意味着涉及多个数据节点的分布式事务保证在所有节点上都成功或在任何节点上都不成功。此保证由 两阶段提交协议 提供,该协议用于在 TimescaleDB 中实现分布式事务。
但是,分布式超表的读取一致性与常规超表不同。由于分布式事务是跨多个节点的各个事务的集合,因此由于网络传输延迟或其他小的波动,每个节点可以在略微不同的时间提交其本地事务。因此,访问节点无法保证跨所有数据节点的完全一致的数据快照。例如,当另一个并发写入事务处于其提交阶段并且已在某些数据节点上提交但未在其他数据节点上提交时,分布式读取事务可能会启动。因此,读取事务可以在一个节点上使用包含另一个事务修改的快照,而在另一个数据节点上的快照可能不包含它们。
如果您在分布式事务中需要更强的读取一致性,那么您可以使用跨所有数据节点的一致快照。但是,这需要大量的协调和管理,这可能会对性能产生负面影响,因此默认情况下未为分布式超表实现。
如果您在多节点环境中使用 Timescale,则连续聚合有一些额外的注意事项。
当您在多节点环境中创建连续聚合时,连续聚合应在访问节点上创建。虽然可以在数据节点上创建连续聚合,但它会干扰访问节点上的连续聚合,并可能导致问题。
当您在访问节点上刷新连续聚合时,它会计算单个窗口来更新时间桶。如果实际更新的行数很少,但分布很广,这可能会减慢您的查询速度。如果网络延迟很高(例如,如果您有远程数据节点),则情况会更糟。
失效日志保存在数据节点上,其目的是限制需要传输的数据量。但是,某些语句会将失效直接发送到日志,例如,当删除数据块或截断超表时。与本地更新相比,此操作可能会降低性能。此外,如果您刷新不频繁但对超表的更改很多,则失效日志可能会变得非常大,这可能会导致性能问题。确保维护您的失效日志大小以避免这种情况,例如,通过频繁刷新连续聚合。
有关设置多节点的更多信息,请参阅多节点部分
关键词
在此页面上发现问题?报告问题 或 在 GitHub 上编辑此页。