time_bucket 函数允许您将 超表 中的数据聚合到时间桶中。例如:5 分钟、1 小时或 3 天。它类似于 PostgreSQL 的 date_bin 函数,但它在桶大小和开始时间方面为您提供了更大的灵活性。
时间分桶对于处理时间序列数据至关重要。您可以使用它来汇总数据以进行分析或降采样。例如,您可以计算过去一天传感器读数的 5 分钟平均值。您可以根据需要执行这些汇总,或在 连续聚合 中预先计算它们。
本节介绍时间分桶的工作原理。有关 time_bucket 函数的示例,请参阅关于 使用时间桶 的部分。
时间分桶将数据分组到时间间隔中。使用 time_bucket,间隔长度可以是微秒、毫秒、秒、分钟、小时、天、周、月、年或世纪的任意数量。
time_bucket 函数通常与 GROUP BY 结合使用以聚合数据。例如,您可以计算桶内值的平均值、最大值、最小值或总和。

原点决定了时间桶的开始和结束时间。默认情况下,时间桶不会从数据中最早的时间戳开始。通常有一个更符合逻辑的时间。例如,您可能在 00:37 收集了第一个数据点,但您可能希望您的每日桶从午夜开始。同样,您可能在星期三收集了第一个数据点,但您可能希望您的每周桶从星期日或星期一开始计算。
相反,时间是根据来自原点的间隔划分为桶的。下图显示了如何使用 2 周桶的示例。桶的第一个可能的开始日期是 origin。桶的下一个可能的开始日期是 origin + bucket interval。如果您的第一个时间戳没有正好落在可能的开始日期上,则立即在前的开始日期将用作桶的开始。
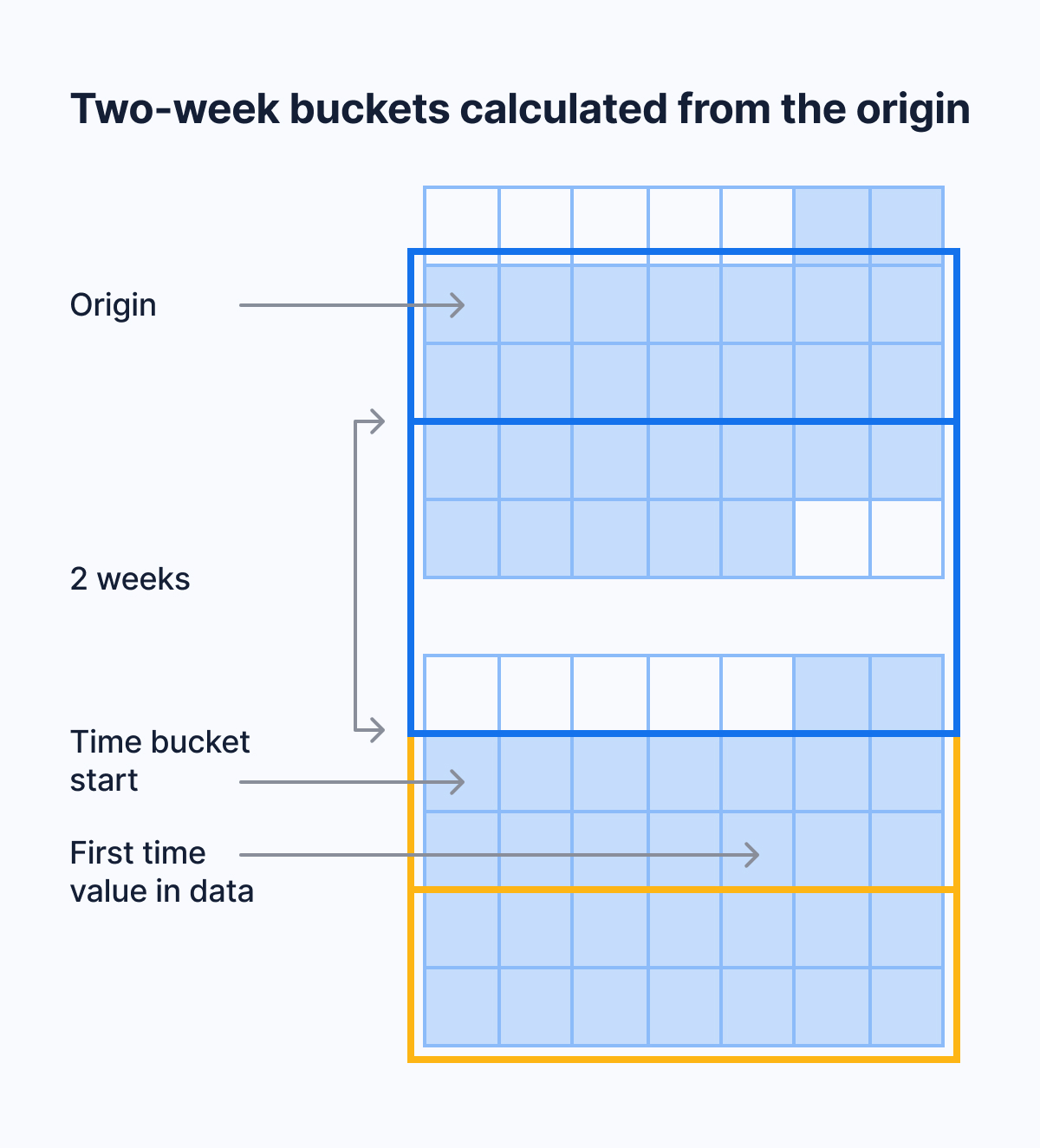
例如,假设您数据最早的时间戳是 2020 年 4 月 24 日。如果您按两周的间隔分桶,则第一个桶不会从 4 月 24 日(星期五)开始。它也不会从 4 月 20 日(紧随其后的星期一)开始。它从 4 月 13 日开始,因为您可以通过从 2000 年 1 月 3 日(在本例中为默认原点)以两周的增量计数来达到 2020 年 4 月 13 日。
对于不包含月份或年份的间隔,默认原点是 2000 年 1 月 3 日。对于月份、年份或世纪间隔,默认原点是 2000 年 1 月 1 日。对于整数时间值,默认原点是 0。
这些选择使时间桶的时间范围更加直观。因为 2000 年 1 月 3 日是星期一,所以每周时间桶从星期一开始。这符合 ISO 计算日历周的标准。每月和每年时间桶使用 2000 年 1 月 1 日作为原点。这允许它们从日历月或年的第一天开始。
如果您喜欢其他原点,您可以使用 origin 参数 自行设置。例如,要使周从星期日开始,请将原点设置为 2000 年 1 月 2 日,星期日。
原点时间取决于您的时间值的数据类型。
如果您使用 TIMESTAMP,默认情况下,桶开始时间与 00:00:00 对齐。每日和每周桶从 00:00:00 开始。较短的桶从您可以从原点日期 00:00:00 以桶增量计数得到的时间开始。
如果您使用 TIMESTAMPTZ,默认情况下,桶开始时间与 00:00:00 UTC 对齐。要将时间桶与另一个时区对齐,请设置 timezone 参数。
关键词
在此页面上发现问题?报告问题 或 在 GitHub 上编辑此页面。